

3. 反向传播
Gradient Descent做法就是对于loss function做微分, 然后更新$\theta$, 但是问题是如何有效的处理上百万的参数?
因此反向传播做的事情就是让梯度计算更加有效率。
chain Rule
也就是说dz会被dx和dy影响。
对于识别的问题,loss是cross entropy,也就是交叉熵。对于sumCrossEntropy做微分的话就是可以写成这个式子。
通过chain rule可以得到$\frac{\partial C}{\partial Z}$是可以写成$\frac{\partial z}{\partial w}\frac{\partial C}{\partial z}$的那么foward pass就代表$\frac{\partial z}{\partial w}$的过程,backward pass代表$\frac{\partial C}{\partial z}$的过程
那么这个计算很简单, 就是根据w之前接的input值就是偏微分的值。
Forward pass
知道微分的值跟input有关后,那么计算就很简单,理解也很容易,对于第一层的值就 ...

ocr算法调研以及未来工作方向
OCR简介OCR,optical Character Recognition,目的是进场景的文字识别
这里泛指文字检测识别,扫描文档以及自然场景的文字识别
OCR应用
车牌识别
身份证,护照,户口本等名片识别
火车票,快递单识别
发票,医疗表单识别
视频实时翻译,基于文字内容字母翻译,安全监控
OCR技术难点
文字弯曲(打印的字体有一些问题)
背景干扰(降噪,属于图像恢复)
字体多变(字体识别需求)
拍摄模糊(高斯处理)
文字检测算法目前的文字检测算法有两种,一种基于回归,一种基于分隔
CTPN
SEGLINK
Textboxes/Textboxes++
East
LOMO
SAST
CRAFT
优点:对规则文本检测效果较好
缺点:无法准确检测不规则形状文本
基于分隔的算法
Pixel embedding
SPCNet
PSENet
PAN
DB
优点: 对不同形状文本检测效果较好,但是无法检测不规则形状文本
缺点:后处理复杂耗时,重叠文本效果差
文本检测算法训练文本检测算法对于每一条数据,对应一个强label标注的txt,对应检测的框获得一个对应的js ...

苏格拉底的前辈-米利都学派
泰勒斯
过于渴望天上的事情,以至于看不到脚下的东西
如果从理想主义上说,那就是坚定不移的去追逐自己想要的东西,但是如果换一个角度,是否就代表不够脚踏实地?在我看来,只有被称为家的人才有权利以及能力去追逐做研究。
关于他的小故事也很这句名言有关,他精通天文学,因此可以预测来年的收成,通过预测橄榄的丰收而挣了一大笔钱,并向人类证明哲学家是很容易发财的,只是他们不感兴趣。
概念,抽象化这些名词是因为哲学而拥有的。泰勒斯尝试解释事物的结构。不论是土壤,云和海洋,不论形态以及事物之间有多大差异,但是事物本身的根本有一定程度的相似性,这个物质就是水。
虽然这个解释性的回答是错误的,但是能够想出或者尝试提出世界的本质是什么这个问题。世界的构成不再充斥神话,而转向了科学。我觉得西方哲学家可以想探寻事物的一般性规律,想总结一般性这点和中国文化的确有明显的不同,中国的哲学并不好奇构成,更多的在乎精神的和谐,天人合一的状态。这点上说,泰勒斯很了不起,因为他给所有之后的西方哲学家指了一条方向,去探究的方向。
阿娜克西曼德他是泰勒斯的学生,他随着泰勒斯的事物的构成问题延伸思考下去,只是他不认同事物构成的本质是 ...
有关ocr api的调研
ocr开源情况ocr目标检测模型百度的paddlehub使用了文本检测模型,主要模型为east,骨干网络为resnet,精度如下:
模型
骨干网络
precision
recall
Hmean
EAST
ResNet50_vd
85.80%
86.71%
86.25%
EAST
MobileNetV3
79.42%
80.64%
80.03%
DB
ResNet50_vd
86.41%
78.72%
82.38%
DB
MobileNetV3
77.29%
73.08%
75.12%
SAST
ResNet50_vd
91.39%
83.77%
87.42%
ocr目标识别模型文本识别使用的是CRNN
模型
骨干网络
Avg Accuracy
模型存储命名
Rosetta
Resnet34_vd
80.9%
rec_r34_vd_none_none_ctc
Rosetta
MobileNetV3
78.05%
rec_mv3_none_none_ctc
CRNN
Resnet34_vd
82.76%
rec_r34_vd_none_b ...

2.深度学习简介
up and downs of Deep Learning1958年发明了感知机,perceptron,也就是linear model。
1969年mit发布了论文发表对于deep learning而言是有极限的,因为毕竟还是线性方程组合模型。
在这个期间也有很多关于深度学习的应用,比如图像识别晴天阴天,但是后来发现此时的识别度并不高,更多是由于亮度值而参考。并没有真正的捕捉到特征。
于是在1980年代, multi-layer perception的技术已经比较深入了,和现在的deep learning并没有显著的差别。
1986年出现了backpropagation,当时的问题是超过三个以上的hidden layter不够有效
但是在1989年的时候,却发现只要一个hidden layter就可以是function,就够强了,所以根本没必要弄那么多的layer,因此这个方法就短时间不够有效,大家更多把精力集中在svm。
2006年rmb initialization的提出使深度学习的技术有了突破。现在的深度学习和1980年的感知机有何不同?不同在于梯度下降的方式不同,虽然这个模型非 ...

表格识别综述
表格识别方法综述
今日任务:搭建环境,尝试理解梳理之前同事写的ocr代码, 并对ocr表格技术写简要综述,明确未来任务计划,参考了一些github资料.
1. 背景表格大小,种类与样式复杂
目前任务是关于通用表格识别的任务,表格识别是下属于文档识别的领域, 具体任务是通过表格获取和访问数据,获得有效信息,并且重构为表格类型. 目前对于这一问题的研究组合要通过图神经网络GCN, R-CNN,FCN以及CGAN等方法模型识别训练.
2. 任务划分表格识别包括表格检测和表格结构体识别两个子任务
表格检测(table detection): 检测表格外框, 方法:目标检测,实例检测,可以用Yolov5, masrcnn等方式检测
将表格分割为块状, 这里的分割通过表格线划分,同时包含了,表格单元线的检测
表格结构识别(Table Structure Recognition):通过对表格的数据内容分块,提取出表格中的数据与结构信息,得到行列线条的分布和单元格之间的逻辑结构,也称为表格文档重建
3. 表格分类按照有无边目前有三种表格类型
无边框表格/无痕迹线
少量边框表格&# ...

迪仔的java学习教程
前言:
因为我不算教师,而且理论知识储备也不够详尽,我能做的就是整合ucb的cs61b神课和廖学锋老师的java课程来做一些梳理,计算机是一门工科语言,最需要的就是不断的练习,在联系中理解这些内存机制,数据结构。我希望宝宝可以尽力做一些作业,因为这些作业是国外的大学教授,成千上万的助教花心思布置的作业,目的是让你领会理解,学习是一件辛苦的事情,希望我们一起努力进步。
1. Why Study Algorithms or Data Structures?原因是想做一些有意思的,漂亮的东西。
链接: https://youtu.be/BIjj3Qcmbf4
https://www.youtube.com/watch?v=pp1NWRDl0pI
有关流体渲染的一些建模,更多的就不放了,我们快点进入正题
2. 从hello world开始12345public class HelloWorld { public static void main(String[] args) { System.out.println("Hello worl ...
deeplabv3训练结果
1. deeplabv3DeepLabv是由谷歌研发的语义图像分割模型, v3的主要变化如下:
使用了Multi-Grid 策略,即在模型后端多加几层不同 rate 的空洞卷积:
将 batch normalization 加入到 ASPP模块
ASPP能够有效的捕获多尺度信息
有关aspp,这是五个分支,然后通过不同膨胀卷积特征提取,然后堆叠并且整合特征。
本次训练用的是Nclasses =2,模型骨架为mobilenet的参数,mobilenet适合小型的分割预测,对于多种物体在一张图的分割模型,适合nclasses > 2,骨架选择xception.
50次训练后效果还可以,需要明天继续调整参数
2. 标签图对比
左图为segnet的标签预测图,右图为deeplabv3的标签预测图,可以看出deeplabv3的效果很明显优于segnet,对于轮廓的粗细度更加精确,断连的部分也是连接上了。
左图为项目的标签预测图,右图为deeplabv3的标签预测图,因为项目图有进行修改并且处理,因此肯定是项目图的指静脉效果更好,连接的更好,也没有小点.
最终验证集的v ...

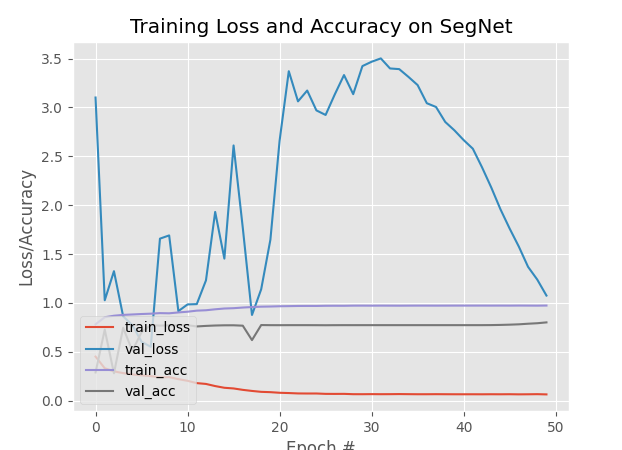
segnet训练结果及新模型
1. segnet调参后结果经过调整参数学习率和batch_size之后,模型达到了较为不错的预期效果。
这是25轮后的效果比对图
从中选择最好效果的模型生成的标签图
500轮后val_acc没有降,因此模型没有太大变化
2. segnet的train,loss,acc,val_acc图
之前训练黑色,各种问题,原来还是因为版本导致的,之前安装的tensorflow版本过高,导致训练慢,并且loss出现了nan ,重新卸载在使用安装后没有了这个问题
3. 使keras搭建deeplabv之前本想使用下载后发现模型并未开源,不能拿来自己训练,只能用公司提供的模型,并且模型适配分割⻋辆,因此作罢,想尝试使用deeplab3本次使用的是google开源的deeplab3模型,目前正在修改数据预处理方式

1.深度学习机器学习基本概念(下)
1. Linear model太简单了?实际函数可能并非是线性关系,而是多个线性函数方程组成的组合方程。
即使参数再准确,仍然无法预测的精准,那么这就被称为模型限制,没有办法模拟真实的状况。因此我们需要更复杂的模型
1.1 构建复杂model假设真实模型为红线所示,那么可以看出这是三个分段线性函数组成的组合函数
那么第一段红线就可以由0线+1线,0线就是$y=b_{1}$的函数,而1线在从0到峰顶过程中设置为slope一致,那么就是$y=w_{2}x+b_{2}$那么同样思路可以有2线和3线
1.2 piecewise linear这种多个线段组成的curver就被称为piecewise linear curve,基本都是常数项加许多线段的组合,只是蓝色function不同。
1.3 beyong piecewise Linear但是有些curve可能是平滑的曲线,但我们仍然可以把它等价为piecewise linear
因为我们可以通过描点近似连线的方式等价。
因此实际上任何一个function都可以通过这种方式逼近。
1.4 beyong pi ...




