
8. what does the error from?
where does the error from?
error到底是因为bias还是因为variance呢
Estimator对于我们要找的关于pokemon的cp值的预测,这个function我们并不知道真实值,对于我们的模型与真实的偏离就是类似于靶子上的偏离。
Bias and Variance of Estimator假设我们做实验期望的值为$\mu$,那么每次实验后偏差的值就是$m_{n}$,那么将所有实验后获得的偏差0值累加后除以N就应该是m的值。
那么偏差散多开就是由variance决定的。
当数量N比较多的情况下,散布会比较集中。而数量N比较小的时候,散布会比较开。
比较的公式如图所示,注意比较用的是biased estimator,而$s^2$普遍小于$\sigma^2$
Low High variance and bias
靶子不偏移,也就是靶子能够距离红中心位置越近越好,这就代表的是bias。
一连串的靶子的点分布集中,这就代表的是variance,也就是分布要低。
Parallel Universes假设我们现在处于不同平行宇宙,每个宇宙我们都抓10 ...
7.回归案例pokemon
pokemon开始啦,来做一个基于对pokemon进化后cp的值的回归预测
estimating the combat power of a pokeom after evolution
体重,身高,血量,种族,目前的cpp都是input,也可以说是特征,$x_{w},x_{h},x_{hp},x_{cp},x_{xhp}$
step 1: Model找一个function set,假设我们猜测的是线性方程,那么就是$y = b + w * X_{cp} $
step 2: Goodness of Function之后就是收集各种pokemon的资料,可以收集记录当一个pokemon进化时的资料,以及进化后的cp变化值,进化后的值就是正确的标签,设定为$\hat y$
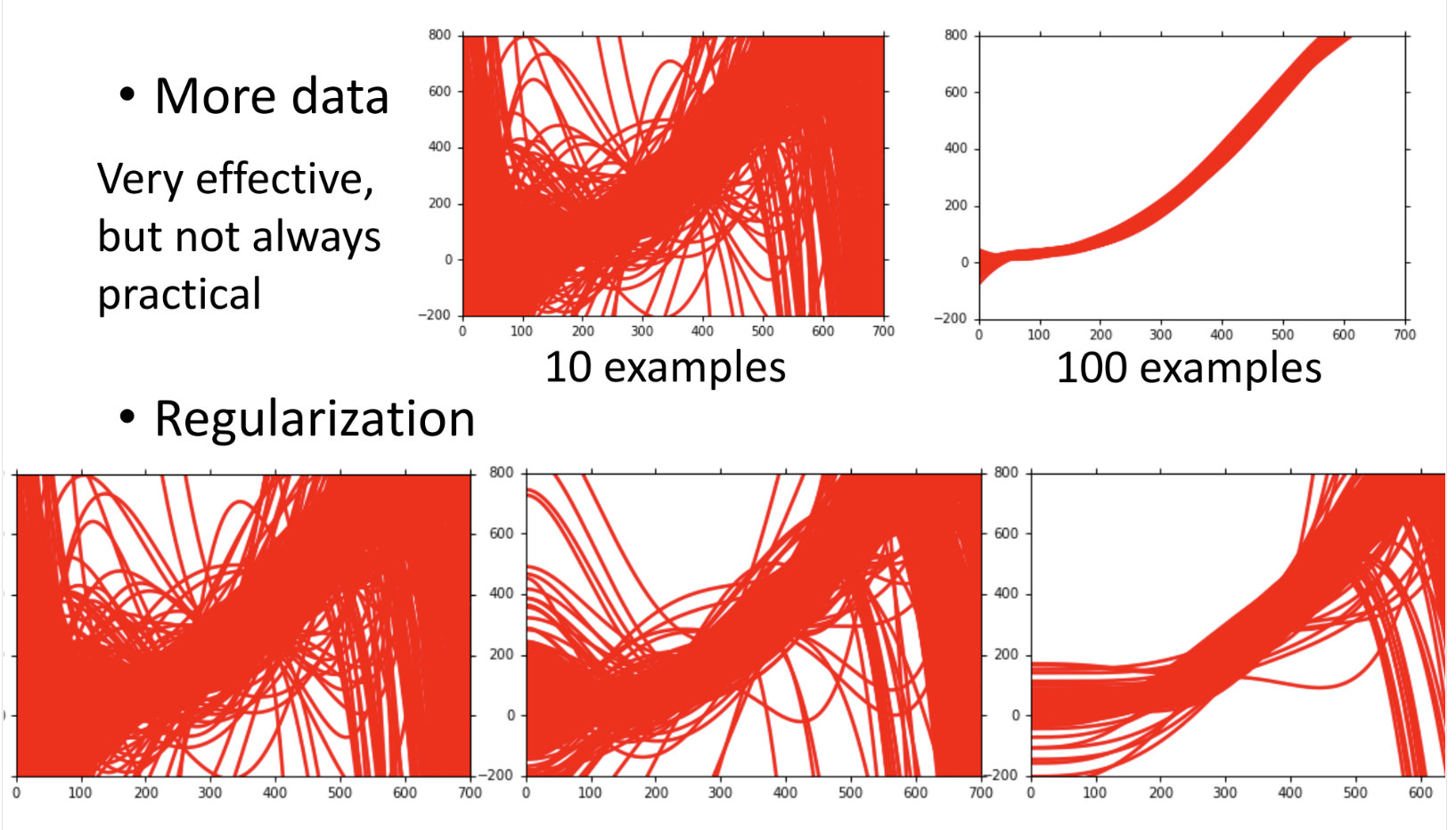
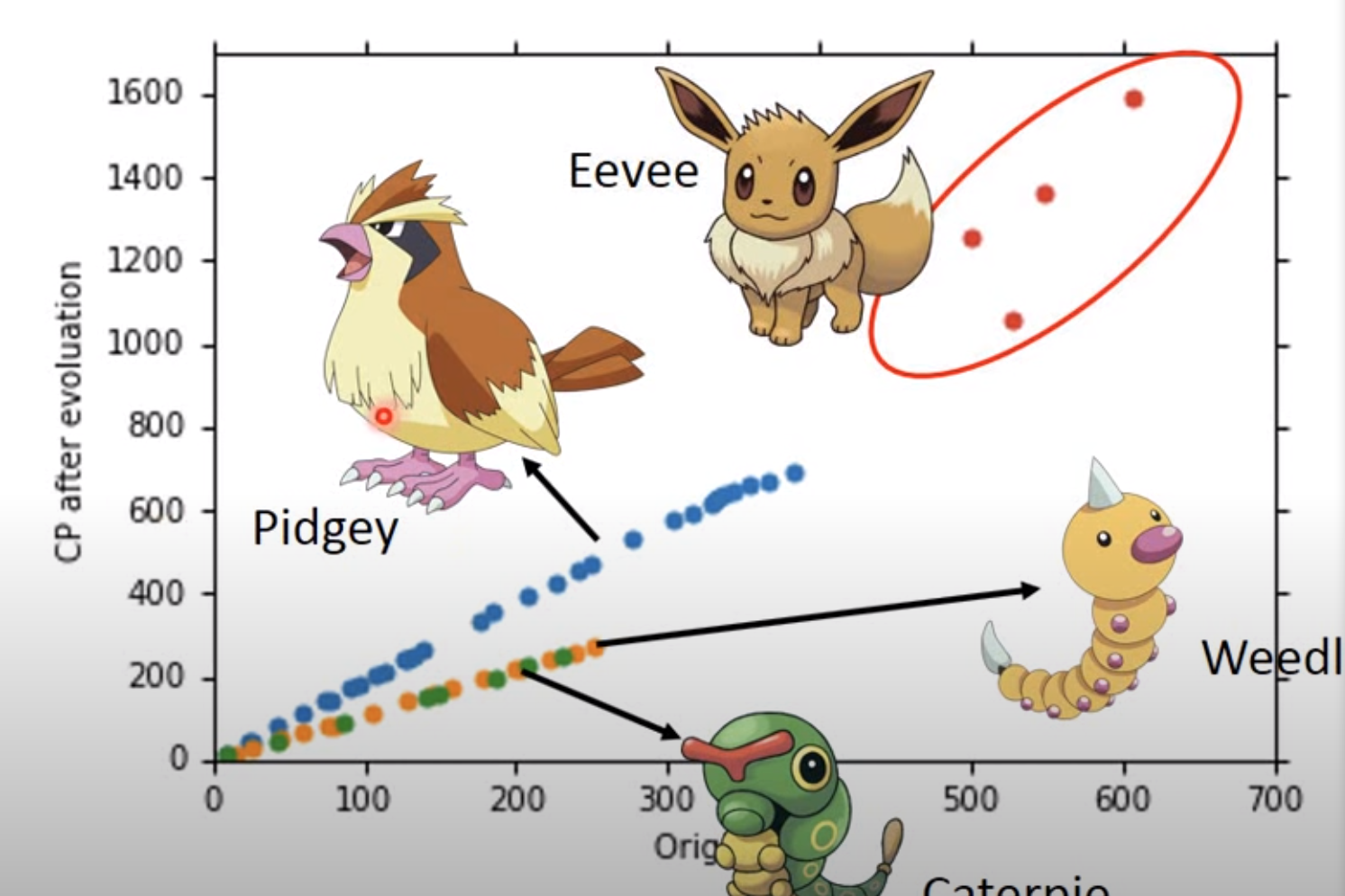
假设目前有10只pokemon,我们画图标记坐标,绘制图如下所示:
可以看到有一些值特别高,这个特别高的值就是伊布,因为伊布比较稀有,他的数值各方面都非常高。
对于如何定义为不好的function,那么就是对于标签值即真实值和函数的预测值的差距特别大,因此loss可以写成estimation err ...
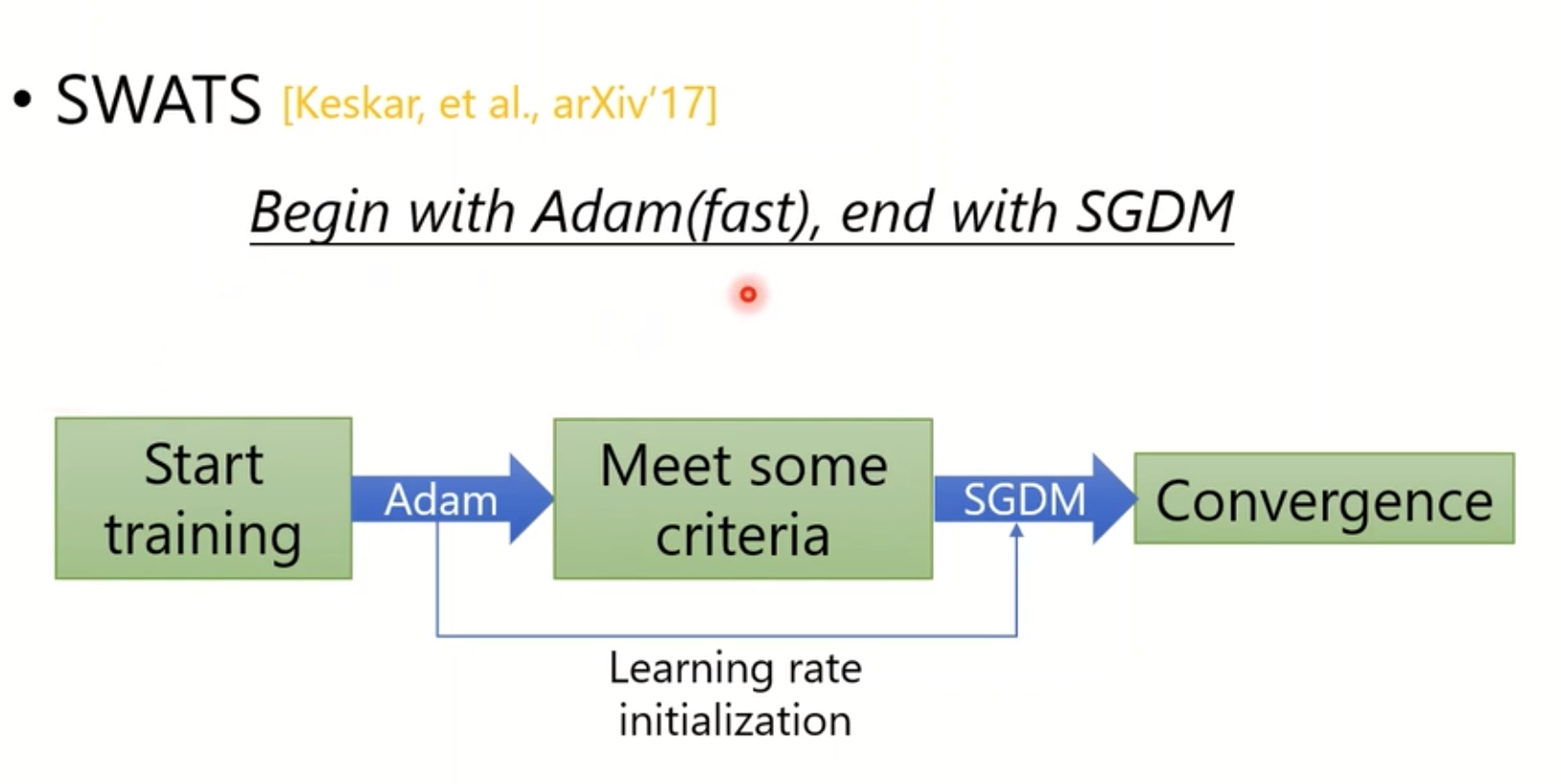
6.new optimizers for Deep Learning
what is optimization about?其实就是找参数能让loss最小,也就是y接近$\hat{y}$
按照理论上来说,我们每次看到的数据以及处理的只有一部分的loss,那么如何确定这个loss是基于整个surface area的呢?
on-line vs off-lineon line的方式是一次只看到一部分的input,off-line是一次性看到全部的input。虽然实际上训练的时候是基于batch的,也就是为了训练更快不可能看到全部资料。
但目前我们的讨论是不考虑实际情况,是在任何点都能拿到全部的input来考虑的
sgd
sgd的方法是基于gradient的方向来决定的。
sgdm引入了momentum,方向基于gradient和之前所有的time step累加,共同决定方向。
原因是上节课说过的,在saddle point的时候为0,可是因为累加了之前的step,因此可以爬出来慢慢继续。
Adagrad解决了在不同的地方使用不同的learning rate,平坦地方的learning rate比较大,陡峭地方的learning rate比较小。
...
5. 类神经网络训练(loss and batch Normalization)
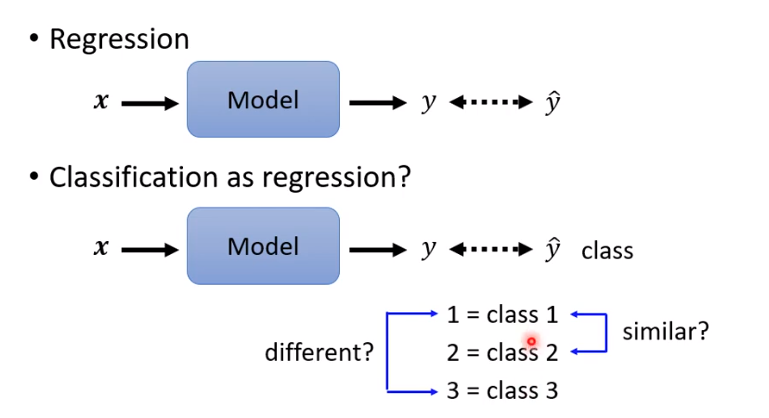
Classification as Regression?
在分类问题中,可以根据输出来定义分类,但是这个分类属于人为定义的,因此不一定完全准确。
class as one-hot vectorone-hot 就是对于给定的class标1,其余为0的方式。
假设我们目前要分类的是只有3个class,那么可以得知输出的向量是包含三个数字的,确定了output是什么形式,就需要修改神经网络,因为原本输出的是一个scalar,只有一个数值。
我们可以对activation的值加上不同的w和b就可以得到三个值
除此之外,分类问题还需要再计算一次softmax,来计算y跟$yhat$的距离。
soft-max的方式就是归一化,把输出的值改为0或者1。
soft-max
公式就是如图所示,假设$y_{1}$,$y_{2}$,$y_{3}$的值为3,1,-3,那么都除以e,e的值是2.7$$e^3 = 20 \quad e^1 = 2.7 \quad e^-3 = 0.05 \\sum(e^3+e^1+e^-3)=22.75 \y_{1}^{‘} &# ...

linux小技巧
向日葵连接断开解决123sudo ap-get updatesudo ap-get upgradesudo apt-get install lightdm 选择lightdm
选择完之后重启,并且记得把设置里的共享全部打开
解压.001, .002, .003文件技巧以TableBank数据集为例,下载了TableBank.zip.001,002,003,004,因此需要先将文件夹整合为一个zip
12cat TableBank.zip* > TableBank.zipunzip TableBank.zip
查询本机ip123456[root@myzdl ~]# curl cip.ccIP : 223.17.42.12地址 : 中国 北京运营商 : 电信数据二 : 北京市 | 联通
表格识别转excel
关于目前任务目前还在通过paddle给的预训练模型训练,目标检测模型目前精度仍然较低,只有百分之40的精度,原因不明。
关于邹九遗留的代码过于复杂看不太明白,很难自己尝试优化,目前通过的是根据PubLayNet数据集训练的表格场景的文字检测来获得目前数据,再判断是否是同一行,同一列文字,最后返回数据,目前精度不高,需要继续训练
难点在于目标返回的坐标的列的点预测会有一些错误,在第四个坐标的时候会突然变大,并不符合一行的坐标,但是如果用opencv的方式计算很慢,效果也不会很好,导致这个列的坐标在列的判断中是有一些困难的。
因此之后几天想多使用英文的表格数据集,来提高表格的识别概率。
opencv的话就是通过膨胀方式然后做位运算找交集的点,这个方法不太适配所有表格的交叉点。
5.类神经网络训练(Learning Rate)
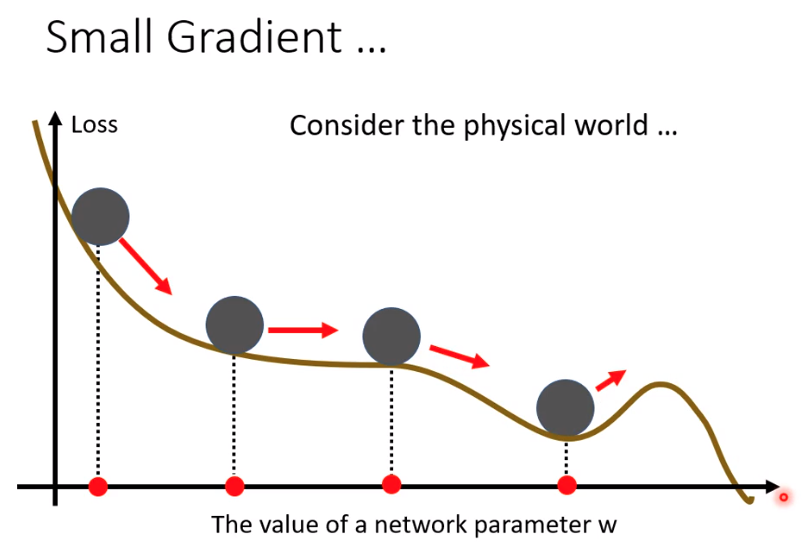
Training stuck not equal Small Gradient
People believe training stuck because the parameters are around a critical point
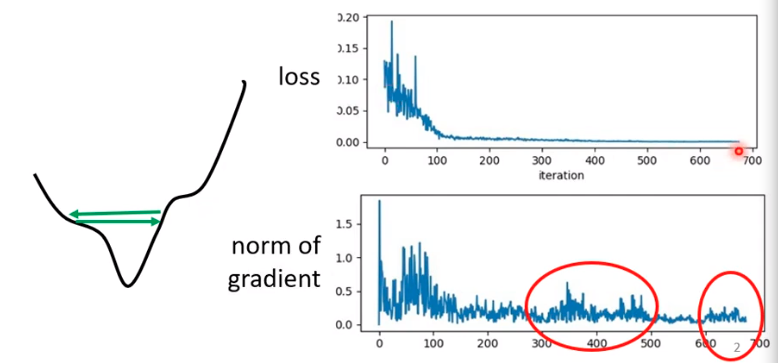
但是并不一定是因为以及在saddle point,有一种可能是震荡在如图所示的峡谷,导致无法下降。
Training can be difficult even without critical pointslearning rate也就是步长如果比这个峡谷距离大,那么就会一直震荡停留在附近,但是如果真的设置非常小的learning rate,是可以慢慢减少,但是同时这也太慢了。
图上可看出来当learning rate为$10^-7$的时候,更新起来是极其慢的,一点点变化就需要100,000updates, 因此我们需要优化我们的算法。
也就是说不同的参数性格分配不同的learning rate
Different parameters needs different learning rate如何自我改变learning rate的大小让 ...
5. 类神经网络训练(batch and momentum)
Batch每次会把训练资料分成几份不同的batch,然后对于每一个batch做gradient,更新参数,然后不断重复。所有的batch做完就是一次epoch
对于每一次epoch都会打乱batch,都会重新分配epoch的方式,被称为shuffle。
Smal Batch vs Large Batch假设我们有20个example,不分batch和分batch查询loss的图为以下
一种是看完所有的example再决定参数,这组方式时间长,但是比较powerful。另一种是只要看完一个example就更新一次参数,因此会比较noisy,花费的时间也较短。
实际上改为small batch和large batch的时间没有多大区别,因为平行运算可以平行处理不同数据。
Parallel Computing对于batch size增加所花的时间有人做了实验,测试就是mnist手写数据测试,如下图所示,batch size在1000以前,batch size设定并不会导致时间增长,只有batch size增长到1000后时间才迅速增长
smaller batch requires lo ...
5. 类神经网络训练(local minima and saddle point)
Optimization Fails becasue.当你如何训练lpss都无法降低的话,应该如何解决呢
有一种猜想是,loss的微分为0
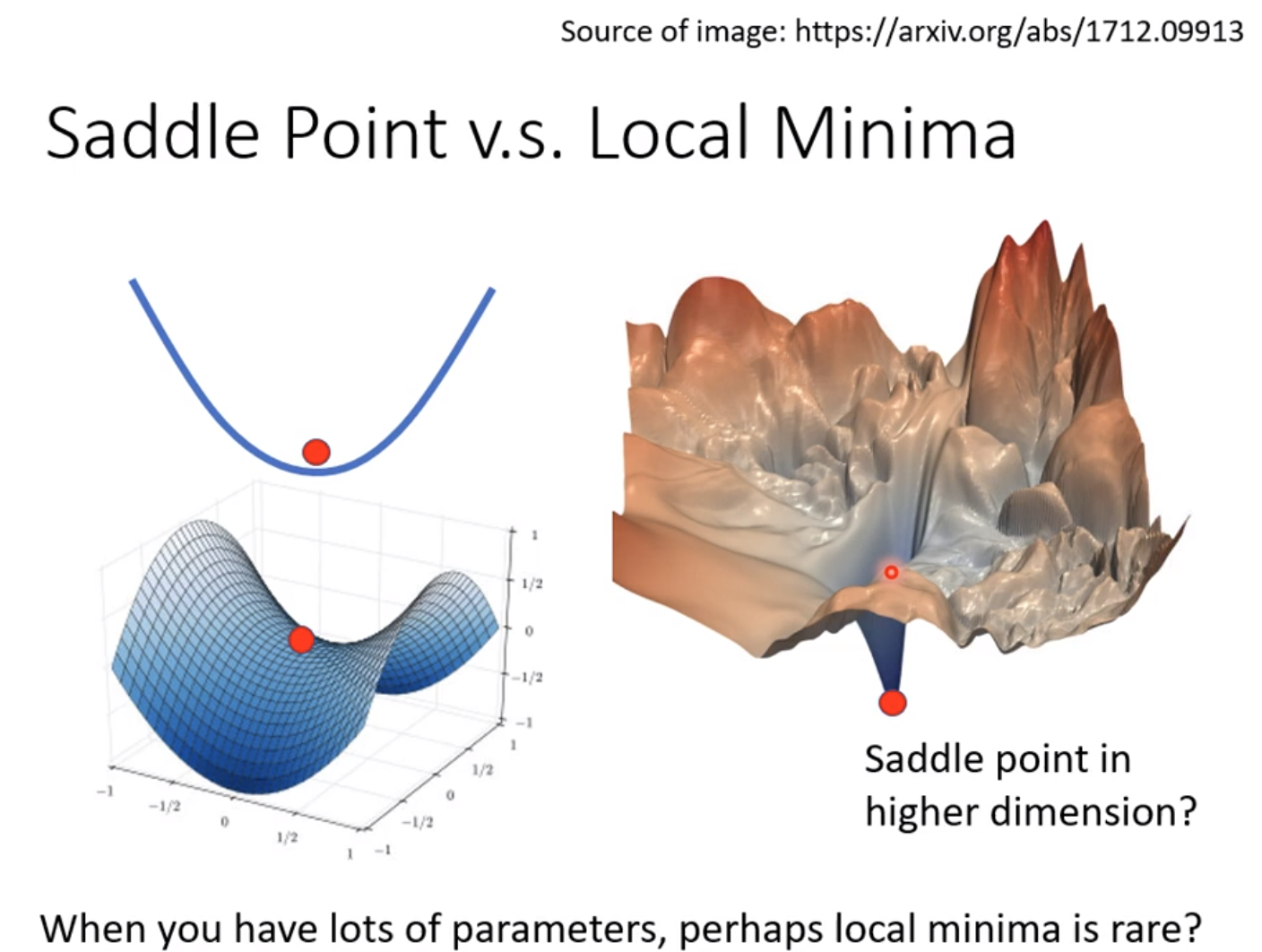
除了local minima导致gradient是0外,saddle point也会gradient为0
local minima的话基本没有办法解决,但是如果是saddle point的话还是可以继续训练的。
Tayler Series Approximation对于判断是saddle还是local的问题,需要用微积分的知识去判断。
这就是泰勒展开式,g是gradient,是衡量$l(\theta)$和$l(\theta’)$的差距。 H是海塞矩阵。
如果绿色的方框式子为0就代表走到了critical point,代表梯度为0,因此可以被近似为只有$l(\theta’)$+红色的式子,而通过hessian可以判断是local min, local max或者saddle point。
Hessian
对于$\theta-\theta’$可以写成v代替,那么式子可以简化为$v^THv$,如果这大于0,就说明$l(\theta)$ > $ ...
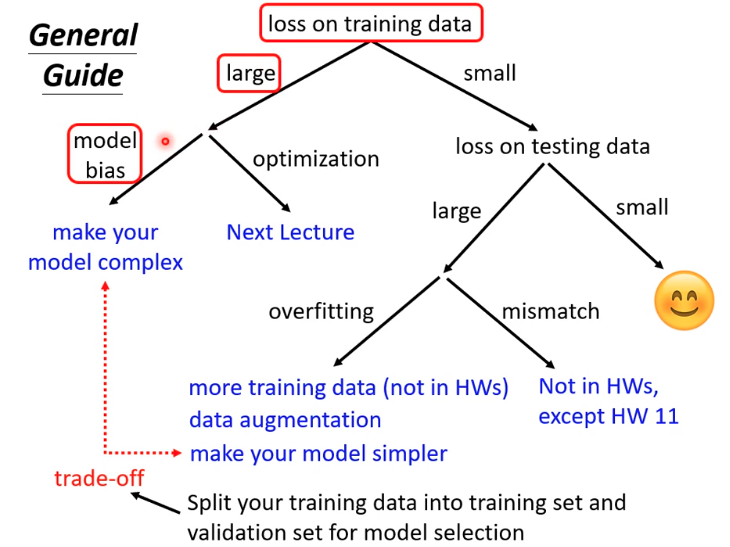
4.机器学习任务攻略
Framework of ML 对于机器学习,training data会包含x与$\hat{y}$对应的。
几次作业都是一样的,作业2语音识别,作业3图像识别,作业4对话识别,只是x和$\hat{y}$不同。
Steps确定function,确定loss function,找到最小loss的参数
但是如何使模型更好呢?
General Guide
Model Bias如果你的function set设定的不好,也就是任何参数的function都不能使loss变小,那么就是function set的问题,解决方式就是重新设计一个function。
比如说对于youtube观看次数的预测,可以优化模型的方式有:
从一天改为56天
增加一些新的feature
Optimization Issue比如梯度下降会卡在local minimum的位置而找不到global minimum。
也就是说通过优化找不到参数低的function,为了能够让要找的function在这里,我们需要把model变大
这两种都是有可能的,可是在训练的时候怎么样才能判断出是model bias的问题, ...




