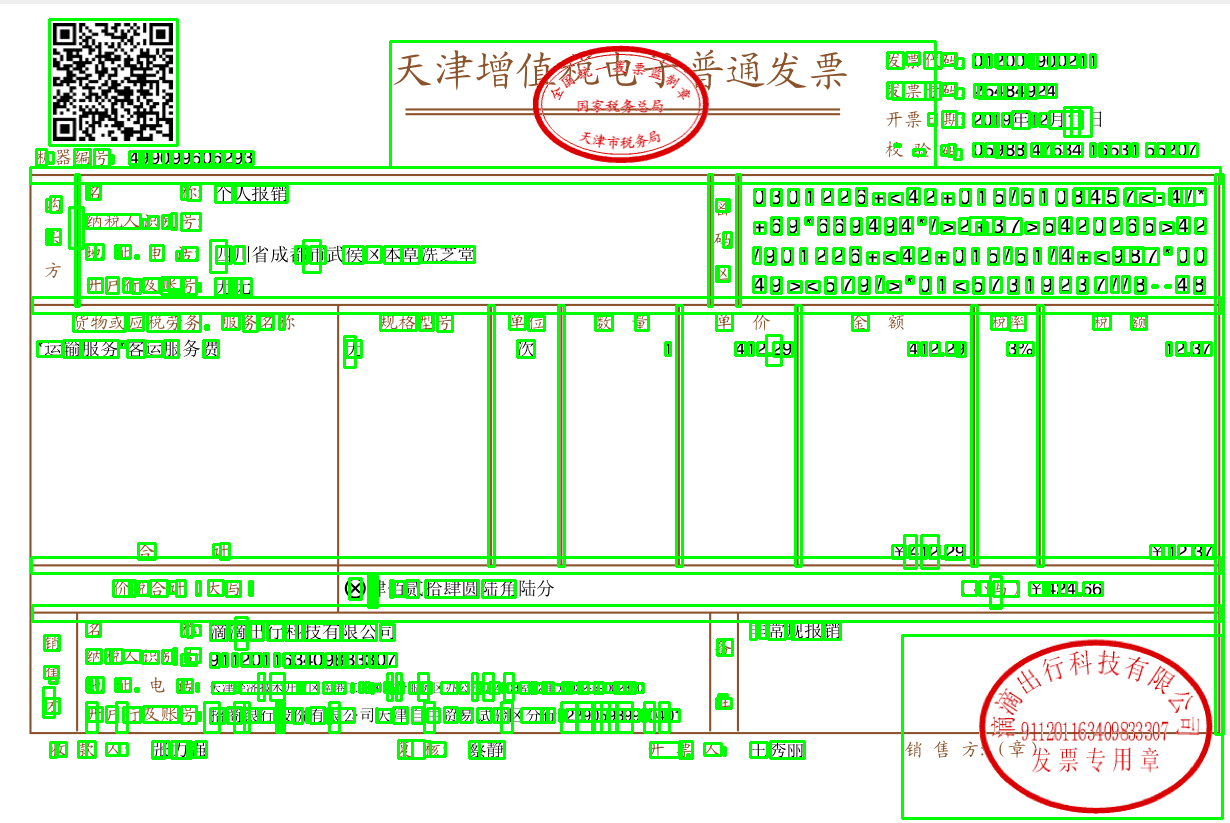
表格识别转excel
关于目前任务
目前还在通过paddle给的预训练模型训练,目标检测模型目前精度仍然较低,只有百分之40的精度,原因不明。
关于邹九遗留的代码
过于复杂看不太明白,很难自己尝试优化,目前通过的是根据PubLayNet数据集训练的表格场景的文字检测来获得目前数据,再判断是否是同一行,同一列文字,最后返回数据,目前精度不高,需要继续训练

难点在于目标返回的坐标的列的点预测会有一些错误,在第四个坐标的时候会突然变大,并不符合一行的坐标,但是如果用opencv的方式计算很慢,效果也不会很好,导致这个列的坐标在列的判断中是有一些困难的。
因此之后几天想多使用英文的表格数据集,来提高表格的识别概率。


opencv的话就是通过膨胀方式然后做位运算找交集的点,这个方法不太适配所有表格的交叉点。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 锅巴要写编译器!