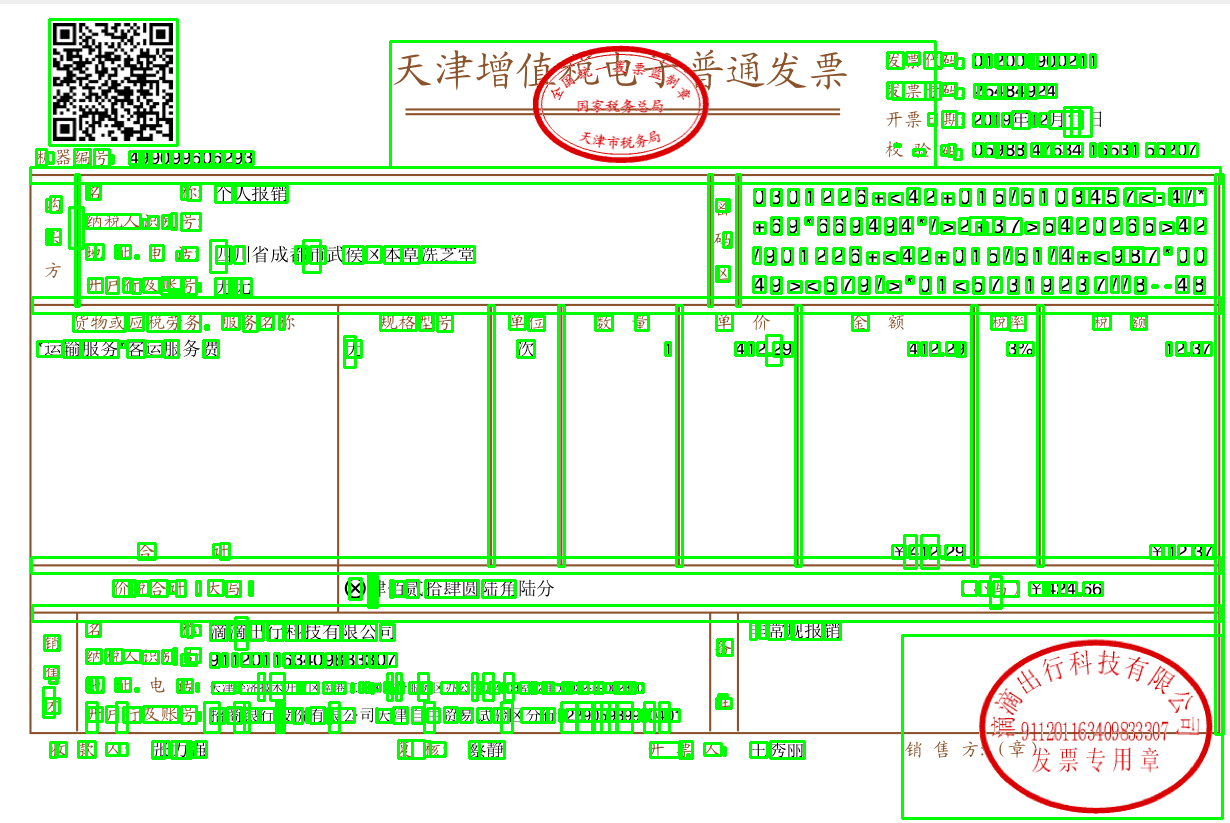
ocr表格识别训练检测
目标检测效果
经过一段时间的训练,精度达到了百分之76.5,还是无法达到精准的表格预测的效果,于是我尝试下载表格数据集在此基础上进行预测。目前预测效果还是不够好。
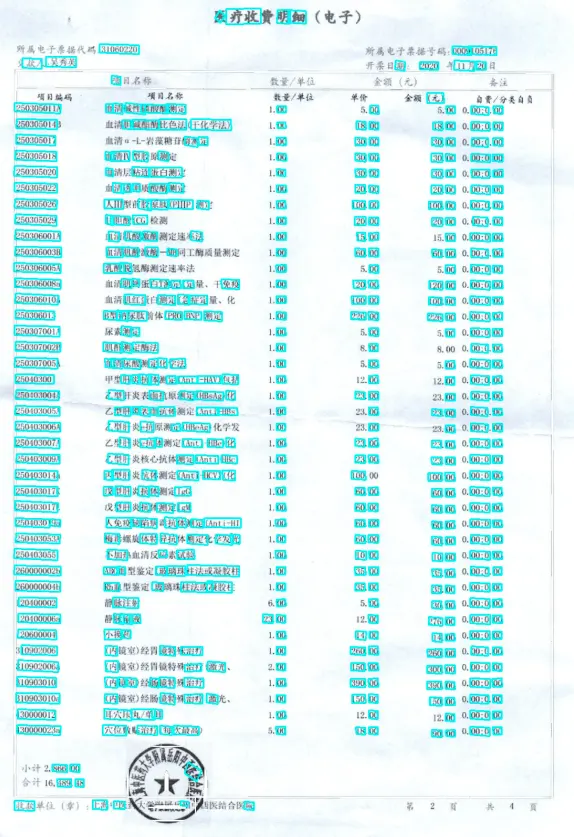
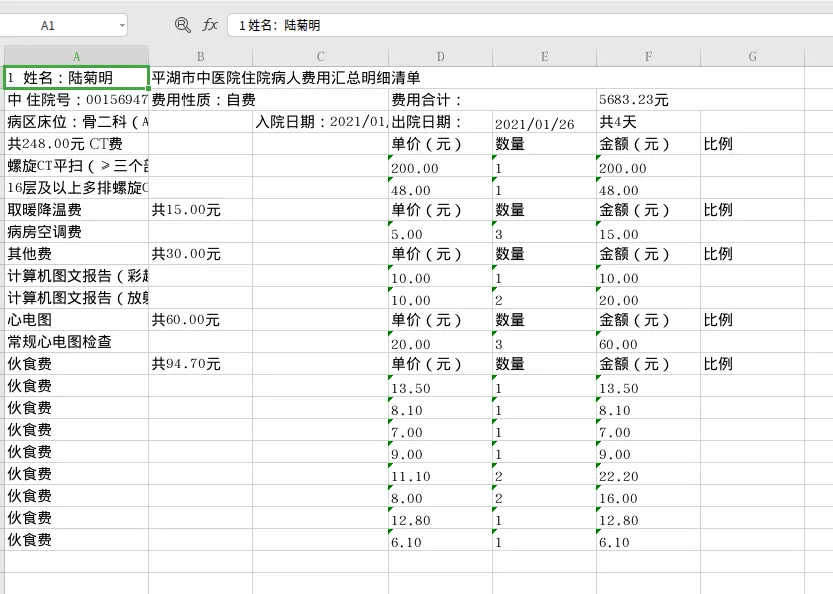
文字识别模型效果
用的是cnnr模型,效果提升不大
表格检测模型
我下载了onedrive上的testbank的表格数据集。目前testbank数据集非常大,解压后有25g的大小
以及Py
这里的表格检测用的是testbank + publaynet数据集,加载一起有50g的数据集,整合为infer的推理模型后,效果还可以。我觉得目前做的效果不可能比paddle更好了
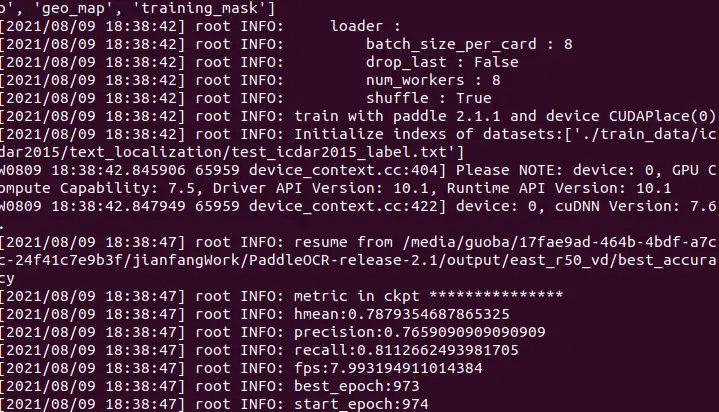
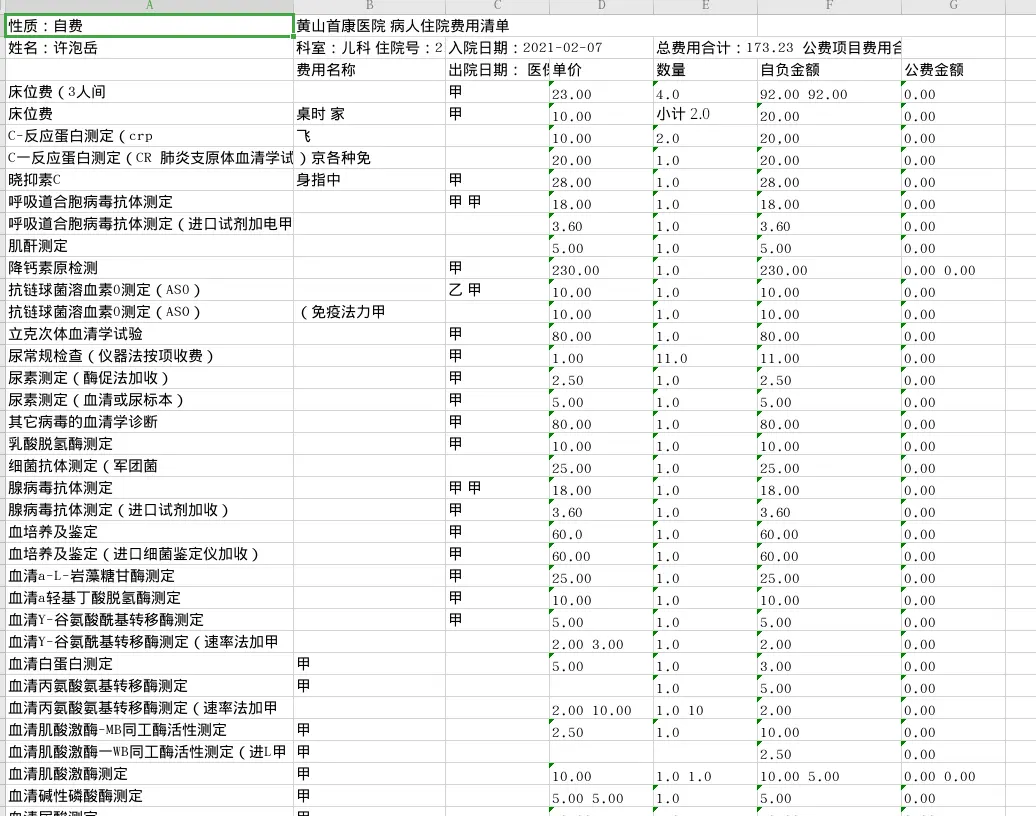
表格基本样式训练模型为ppyolov2_r50vd_dcn_365e_tableBank_word,

比起传统的Opencv处理方式会好很多
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 锅巴要写编译器!