ocr算法调研以及未来工作方向
OCR简介
OCR,optical Character Recognition,目的是进场景的文字识别
这里泛指文字检测识别,扫描文档以及自然场景的文字识别
OCR应用
车牌识别
身份证,护照,户口本等名片识别
火车票,快递单识别
发票,医疗表单识别
视频实时翻译,基于文字内容字母翻译,安全监控
OCR技术难点
- 文字弯曲(打印的字体有一些问题)
- 背景干扰(降噪,属于图像恢复)
- 字体多变(字体识别需求)
- 拍摄模糊(高斯处理)
文字检测算法
目前的文字检测算法有两种,一种基于回归,一种基于分隔
- CTPN
- SEGLINK
- Textboxes/Textboxes++
- East
- LOMO
- SAST
- CRAFT
优点:对规则文本检测效果较好
缺点:无法准确检测不规则形状文本
基于分隔的算法
- Pixel embedding
- SPCNet
- PSENet
- PAN
- DB
优点: 对不同形状文本检测效果较好,但是无法检测不规则形状文本
缺点:后处理复杂耗时,重叠文本效果差
文本检测算法训练
文本检测算法对于每一条数据,对应一个强label标注的txt,对应检测的框获得一个对应的json点。因为目前精度不够高,需要不断训练。
目前使用的数据集是CIDAR2019-LSTV数据集
数据来源于中文街景图像,因为包含的全标注数据较多,可以先使表格检测达到一个比较好的成果,因为目前的表格检测用预训练模型,还是会有一些差距。

目前训练效果精度较差,只有0.37,训练效果较差。
生成表格数据
如果表格数据足够多这一部分可以省去,如果不多则可以使用text_render生成类似表格数据,text_render可以生成带有表格线的数据,包括下划线,这些是在表格中需要
https://github.com/oh-my-ocr/text_renderer
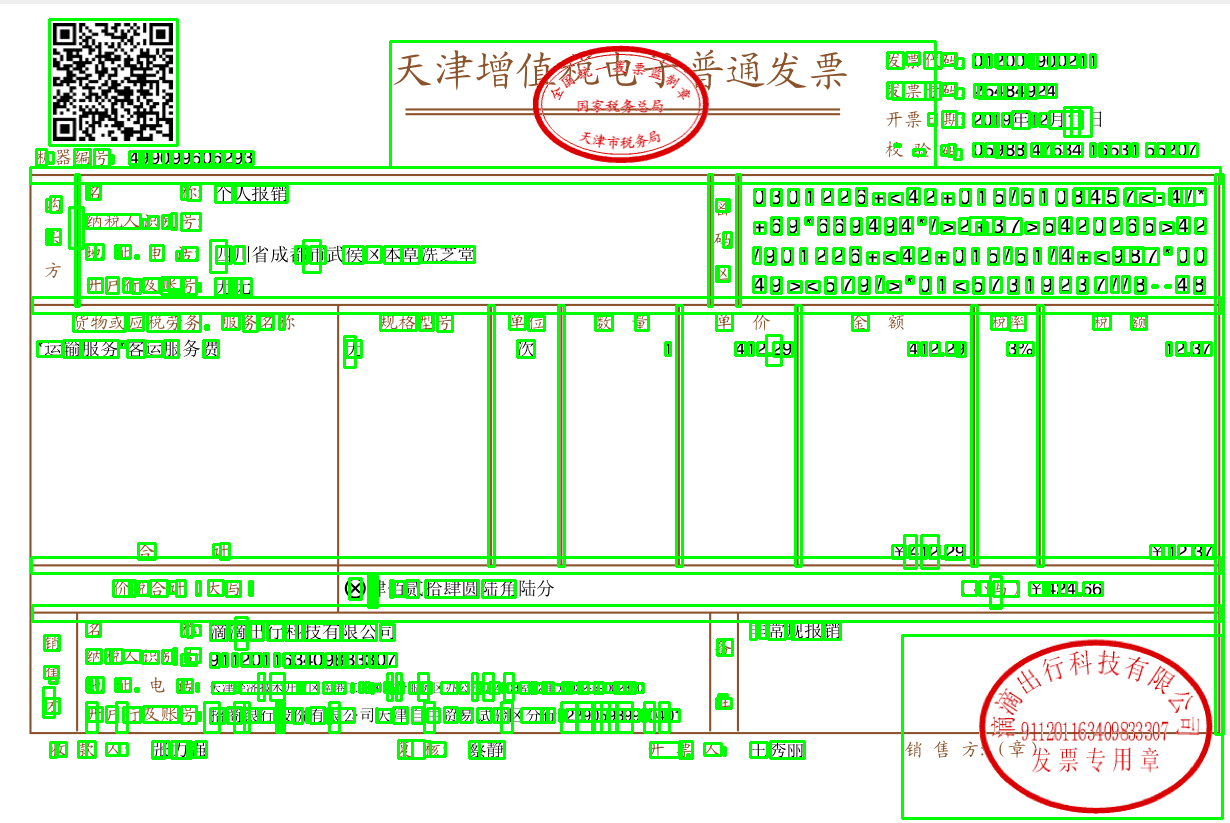
我使用了背景图为票据的照片生成数据,票据背景如下



这样生成的图片会带票据印章,也会带有下划线

会带有二维码

这些图片生成后应该还需要拼接
文字识别
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 锅巴要写编译器!