有关ocr api的调研
ocr开源情况
ocr目标检测模型
百度的paddlehub使用了文本检测模型,主要模型为east,骨干网络为resnet,精度如下:
| 模型 | 骨干网络 | precision | recall | Hmean |
|---|---|---|---|---|
| EAST | ResNet50_vd | 85.80% | 86.71% | 86.25% |
| EAST | MobileNetV3 | 79.42% | 80.64% | 80.03% |
| DB | ResNet50_vd | 86.41% | 78.72% | 82.38% |
| DB | MobileNetV3 | 77.29% | 73.08% | 75.12% |
| SAST | ResNet50_vd | 91.39% | 83.77% | 87.42% |
ocr目标识别模型
文本识别使用的是CRNN
| 模型 | 骨干网络 | Avg Accuracy | 模型存储命名 |
|---|---|---|---|
| Rosetta | Resnet34_vd | 80.9% | rec_r34_vd_none_none_ctc |
| Rosetta | MobileNetV3 | 78.05% | rec_mv3_none_none_ctc |
| CRNN | Resnet34_vd | 82.76% | rec_r34_vd_none_bilstm_ctc |
| CRNN | MobileNetV3 | 79.97% | rec_mv3_none_bilstm_ctc |
| StarNet | Resnet34_vd | 84.44% | rec_r34_vd_tps_bilstm_ctc |
| StarNet | MobileNetV3 | 81.42% | rec_mv3_tps_bilstm_ctc |
| RARE | MobileNetV3 | 82.5% | rec_mv3_tps_bilstm_att |
| RARE | Resnet34_vd | 83.6% | rec_r34_vd_tps_bilstm_att |
| SRN | Resnet50_vd_fpn | 88.52% | rec_r50fpn_vd_none_srn |
paddle-gpu优化问题
关于paddle-GPU,今天倒腾了一天始终没有安装成功,paddle启用gpu的话总是失败,原因是因为cudnn我之前安装的版本是8.0,不兼容。

但是如果是在程序里就直接失败,除非装paddlecpu版本

,因此我决定重新安装cudnn,但是cudnn一直安装出错,原因是显卡兼容错误,可能和cuda版本不对应有关。

gpu参数错误,无法调用。
paddle-gpu安装失败
paddle的各类库都是分开的,我先选择了cpu进行测试查看各类库,目前邹九的程序没有调用gpu成功,因此非常慢

paddle自动化标注
paddle提供了自动标注加识别的可视化软件,目前表格检测的方式仍然不够好,目标检测模型普遍使用,目前来看检测效果优秀,基本都可以检测正确

使用paddle训练目标检测

使用mobilenet训练检测框

训练比较慢,可以之后收集表格的数据来自动标注微调获得表格的标注标签数据,主要还是paddle的cudnn必须完全对照所以现在没有用gpu用的cpu训练,重新配置需要花时间

其他开源项目
目前主要技术还是使用ctpn+crnn+ctc
ctpn被称为目标检测CTPN(Connectionist Text Proposal Network],文本检测与目标检测有区别,因为文本检测具有序列性质,因为文本是由多个字符构成,而不是一个完整的文本线,一般来说是通过文本的每个字符的上线文关系来做的。

通过将文本的选框宽度固定为16,每个字符的高度的位置进行预测,从而获得文本区域位置
这部分的论文原理极其复杂,我还没有认真的看
开源的项目都需要训练表格计算表格位置,并且对于文字识别也要重新计算,邹九做的项目获得数据写入的方式是通过opencv的draw line和draw_rect,还有自己写的draw_log来把文字画在原图上,这些步骤才导致了速度很慢。
如果不需要划线划画框,那么邹九的项目的代码其实通过官方文档几行就可以做完。因为这个代码大部分的任务是在预处理。获得数据如下:

因为邹九的代码写的过长且凌乱,我需要花至少一周整理理解他的代码逻辑,重新写一下代码。
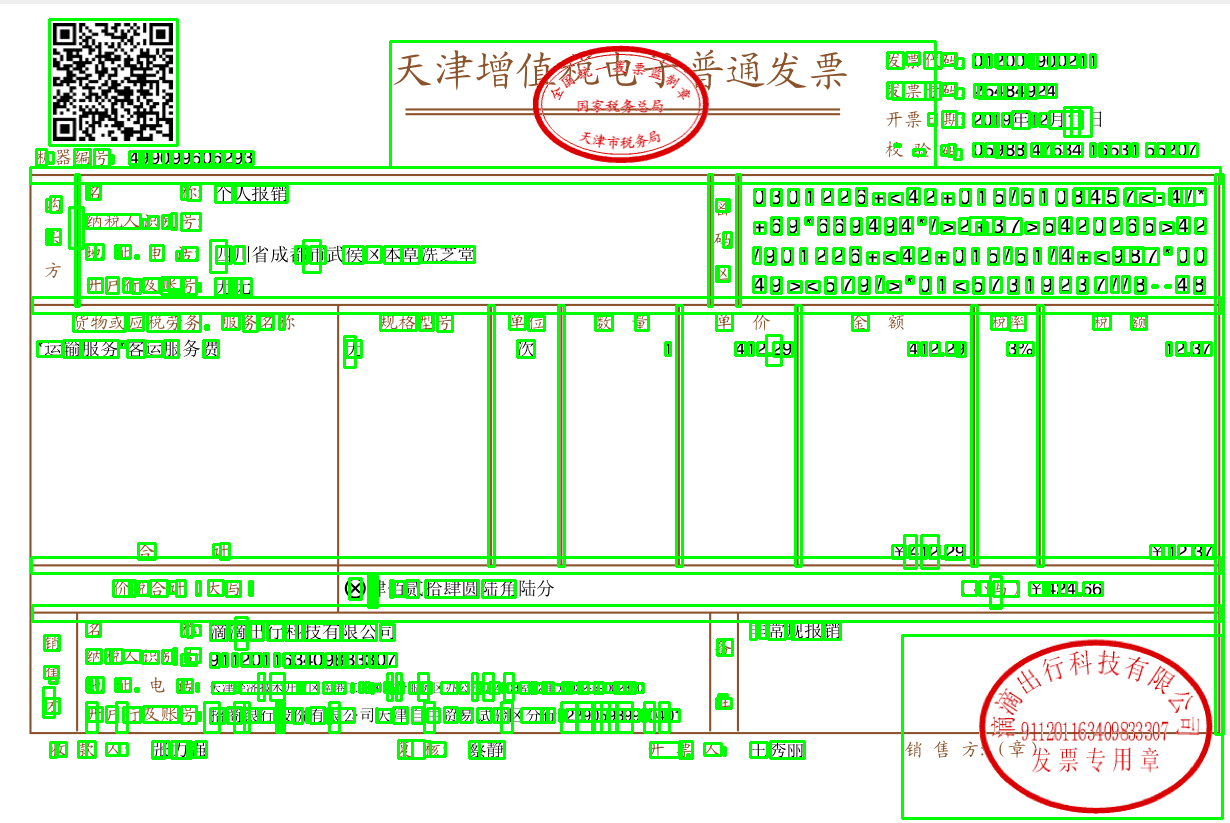
开源的免费ocr的对于表格的识别结果都很差,比如这样的:

对于简单图的识别效果还可以,阿里云华为api只提供json接口返回文字数据,因此尝试也用处不大。
OCR技术难点
- 文字弯曲(打印的字体有一些问题)
- 背景干扰(降噪,属于图像恢复)
- 字体多变(字体识别需求)
- 拍摄模糊(高斯处理)
####### 文字检测算法有两种
目前的文字检测算法有两种,一种基于回归,一种基于分隔
- CTPN
- SEGLINK
- Textboxes/Textboxes++
- East
- LOMO
- SAST
- CRAFT
优点:对规则文本检测效果较好
缺点:无法准确检测不规则形状文本
基于分隔的算法
- Pixel embedding
- SPCNet
- PSENet
- PAN
- DB
优点: 对不同形状文本检测效果较好,但是无法检测不规则形状文本
缺点:后处理复杂耗时,重叠文本效果差