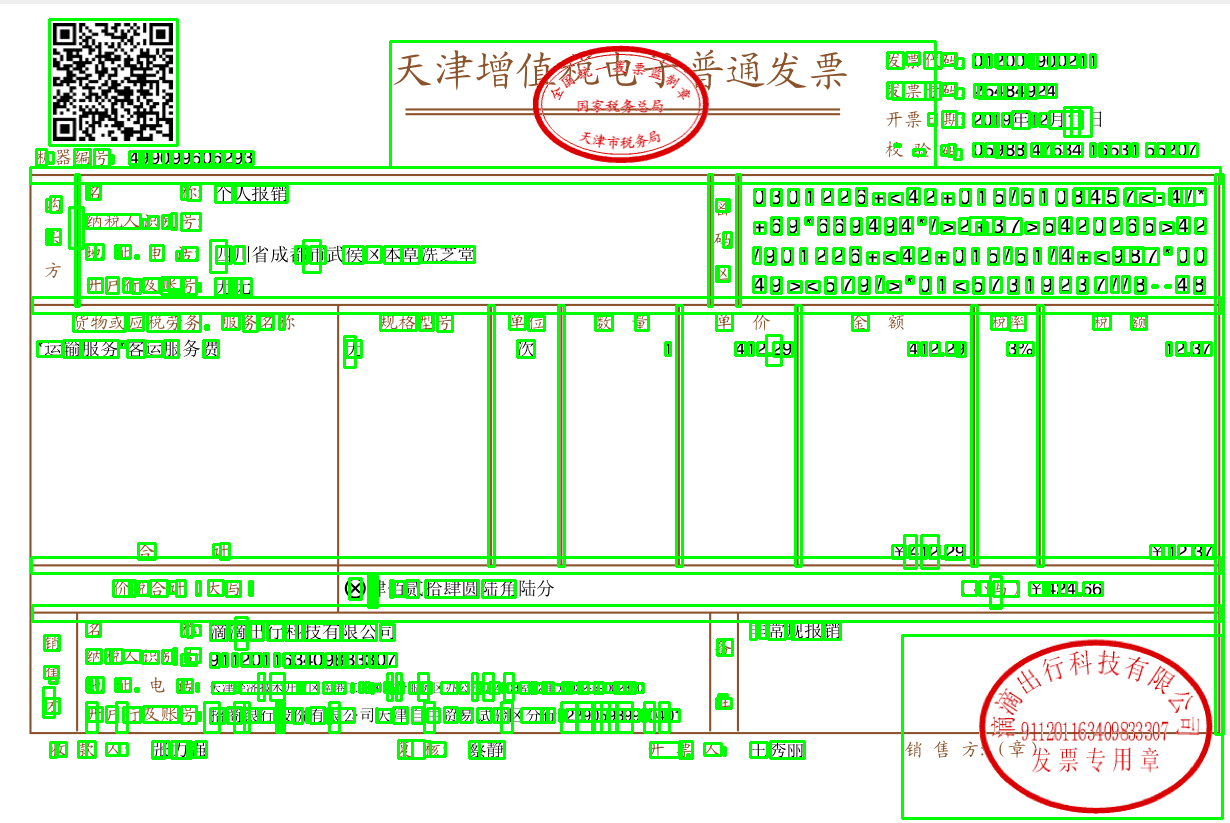
表格识别综述
表格识别方法综述
今日任务:搭建环境,尝试理解梳理之前同事写的ocr代码, 并对ocr表格技术写简要综述,明确未来任务计划,参考了一些github资料.
1. 背景
表格大小,种类与样式复杂
目前任务是关于通用表格识别的任务,表格识别是下属于文档识别的领域, 具体任务是通过表格获取和访问数据,获得有效信息,并且重构为表格类型. 目前对于这一问题的研究组合要通过图神经网络GCN, R-CNN,FCN以及CGAN等方法模型识别训练.
2. 任务划分
表格识别包括表格检测和表格结构体识别两个子任务
- 表格检测(table detection): 检测表格外框, 方法:目标检测,实例检测,可以用Yolov5, masrcnn等方式检测
- 将表格分割为块状, 这里的分割通过表格线划分,同时包含了,表格单元线的检测
- 表格结构识别(Table Structure Recognition):通过对表格的数据内容分块,提取出表格中的数据与结构信息,得到行列线条的分布和单元格之间的逻辑结构,也称为表格文档重建
3. 表格分类
按照有无边目前有三种表格类型
- 无边框表格/无痕迹线
- 少量边框表格/表格线较少
- 完全边框表格/表格线较多
4. 图像预处理
对于表格图进行预处理,通过腐蚀,膨胀,找联通区域,这一部分可以通过opencv的dilate,corression函数处理.
处理后可以对图像进行二值化,再使用霍夫变换,检测出其中的直线,并且把直线对应的巨型区域提取.
这里用的方式是canny+HoughLinesP, 并且涉及一些形态学函数.
预想的效果为以下图效果(网上例子所示)
横向线图

竖向线图

寻找交叉表格

对于如何判断表格,方式是通过找轮廓面积,如果特别小就忽略,否则代表
5. 文字识别api
对于文字识别,谷歌的teressact已经拥有开源代码,并且提供api接口,因此调用接口即可
6. 表格识别相关项目
6.1 table-ocr
对于表格识别目前项目有:https://github.com/Rid7/Table-OCR
基于unet实现的对文档表格的自动检测和重建


模型文件地址: http://gofile.me/4Nlqh/fNHlWzVWo
6.2 chineseocr
7. 搭建环境
1 | conda env create -f img2table.yml |
下一步需要拆分代码,提取表格块,对于yolov5训练,查找如何去除印章方式
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 锅巴要写编译器!