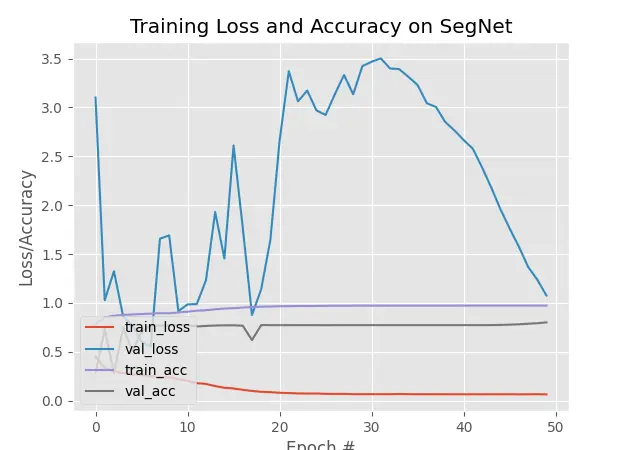
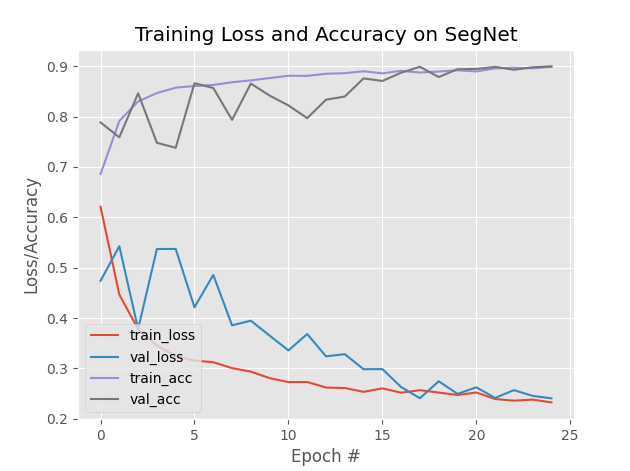
1
2
3
4
5
| [0.4326215719183286, 0.32819647043943406, 0.2906552429000537, 0.27313048268357915, 0.257322250554959, 0.2485936055580775, 0.22558255766828855, 0.21648377254605294, 0.20409626215696336, 0.20077851687868437, 0.18920121863484382, 0.16730001717805862, 0.1484980287651221, 0.13886230066418648, 0.12509861948589485, 0.11312484368681908, 0.10617984918256601, 0.10045421905815602, 0.0941343237956365, 0.08838099787632624, 0.08943186216056347, 0.08403249680995942, 0.08262405296166737, 0.0808349081625541, 0.07744947063426176, 0.07656553431103627, 0.07173504649351041, 0.07101196522514025, 0.06906658746302127, 0.06820937463392814, 0.06713716896871726, 0.06698052963862816, 0.06641608532518148, 0.06359306958814462, 0.06376560181379318, 0.0623266168559591, 0.0641883086413145, 0.06161947716027498, 0.06355244300017754]
[4.0616319417953495, 1.183943474292755, 2.3115387558937073, 2.8657393932342528, 3.0354074954986574, 1.946236801147461, 1.2182376027107238, 0.7115081369876861, 1.212304711341858, 1.451013195514679, 1.378138792514801, 1.8502532362937927, 2.180905544757843, 2.4437543153762817, 2.163941812515259, 1.1873418748378755, 1.8535349130630494, 1.43236004114151, 2.0837748885154723, 1.5460508823394776, 1.2623905420303345, 1.4946002125740052, 0.9569666862487793, 0.9159704208374023, 1.3723973870277404, 1.1889789342880248, 0.9741742849349976, 1.1434678912162781, 0.6369089841842651, 1.9918548583984375, 1.3535398364067077, 1.6862668991088867, 2.3333637952804565, 2.3430821657180787, 1.991876232624054, 1.8902344107627869, 1.8282016038894653, 1.8204568147659301, 1.7553340435028075]
[0.793441899617513, 0.8549221356709799, 0.8724470456441243, 0.8803432782491049, 0.8880141576131185, 0.8906522115071615, 0.9012289047241211, 0.9044830640157063, 0.9091008504231771, 0.9112299919128418, 0.9165944417317708, 0.9268577893575033, 0.9354225158691406, 0.9398213386535644, 0.9463907877604166, 0.9517076492309571, 0.9546644846598308, 0.9573826789855957, 0.960140323638916, 0.9625997543334961, 0.9621321360270182, 0.9645235379536946, 0.9650745391845703, 0.9656690915425619, 0.9672190348307291, 0.9676105817159016, 0.9697905858357747, 0.9700892448425293, 0.9709406534830729, 0.9711839358011881, 0.9717344284057617, 0.9717852274576823, 0.971986452738444, 0.973262882232666, 0.9731442133585612, 0.9738095919291179, 0.9729414621988932, 0.9740989685058594, 0.9732884089152019]
[0.2609233856201172, 0.6673646926879883, 0.7727865219116211, 0.7727920532226562, 0.7727920532226562, 0.7727779388427735, 0.7727840423583985, 0.7730352401733398, 0.7706464767456055, 0.7728574752807618, 0.7730077743530274, 0.7727920532226562, 0.7727920532226562, 0.7727920532226562, 0.7727920532226562, 0.7703588485717774, 0.7727920532226562, 0.7736625671386719, 0.7727758407592773, 0.7733671188354492, 0.7747377395629883, 0.7727874755859375, 0.7983449935913086, 0.7951879501342773, 0.7755756378173828, 0.7867647171020508, 0.7778730392456055, 0.7734188079833985, 0.8260860443115234, 0.7730215072631836, 0.7880279541015625, 0.7789608001708984, 0.772807502746582, 0.7728038787841797, 0.7735385894775391, 0.7745307922363281, 0.7561117172241211, 0.7602884292602539, 0.7596216201782227]
|