1.深度学习机器学习基本概念(下)
1. Linear model太简单了?
实际函数可能并非是线性关系,而是多个线性函数方程组成的组合方程。
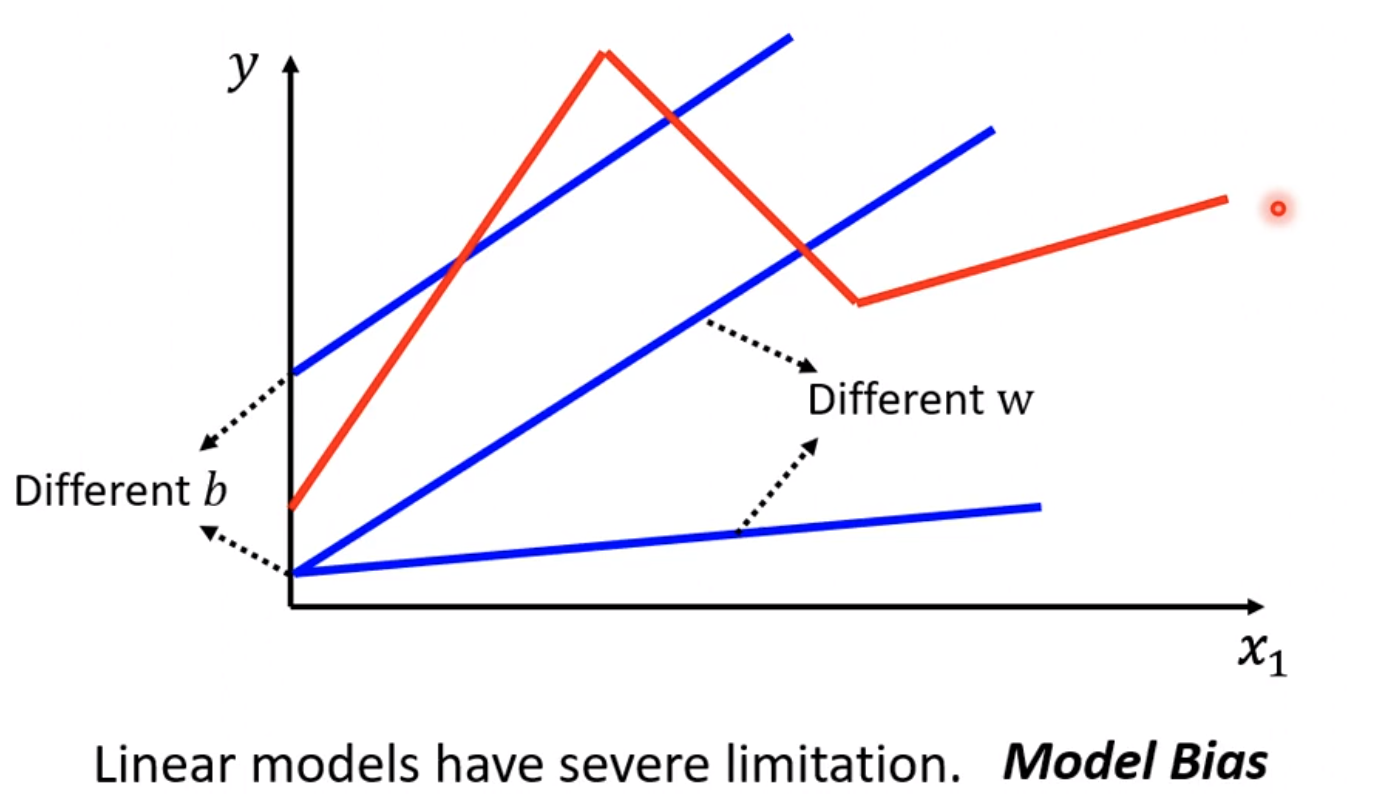
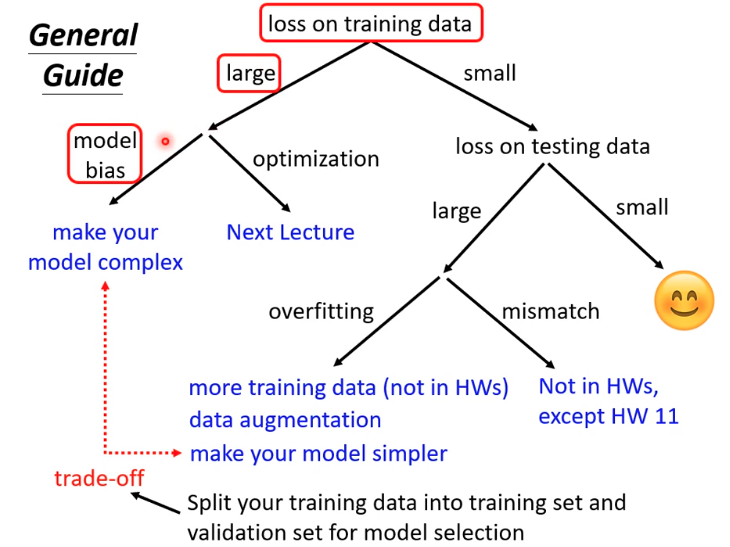
即使参数再准确,仍然无法预测的精准,那么这就被称为模型限制,没有办法模拟真实的状况。因此我们需要更复杂的模型
1.1 构建复杂model
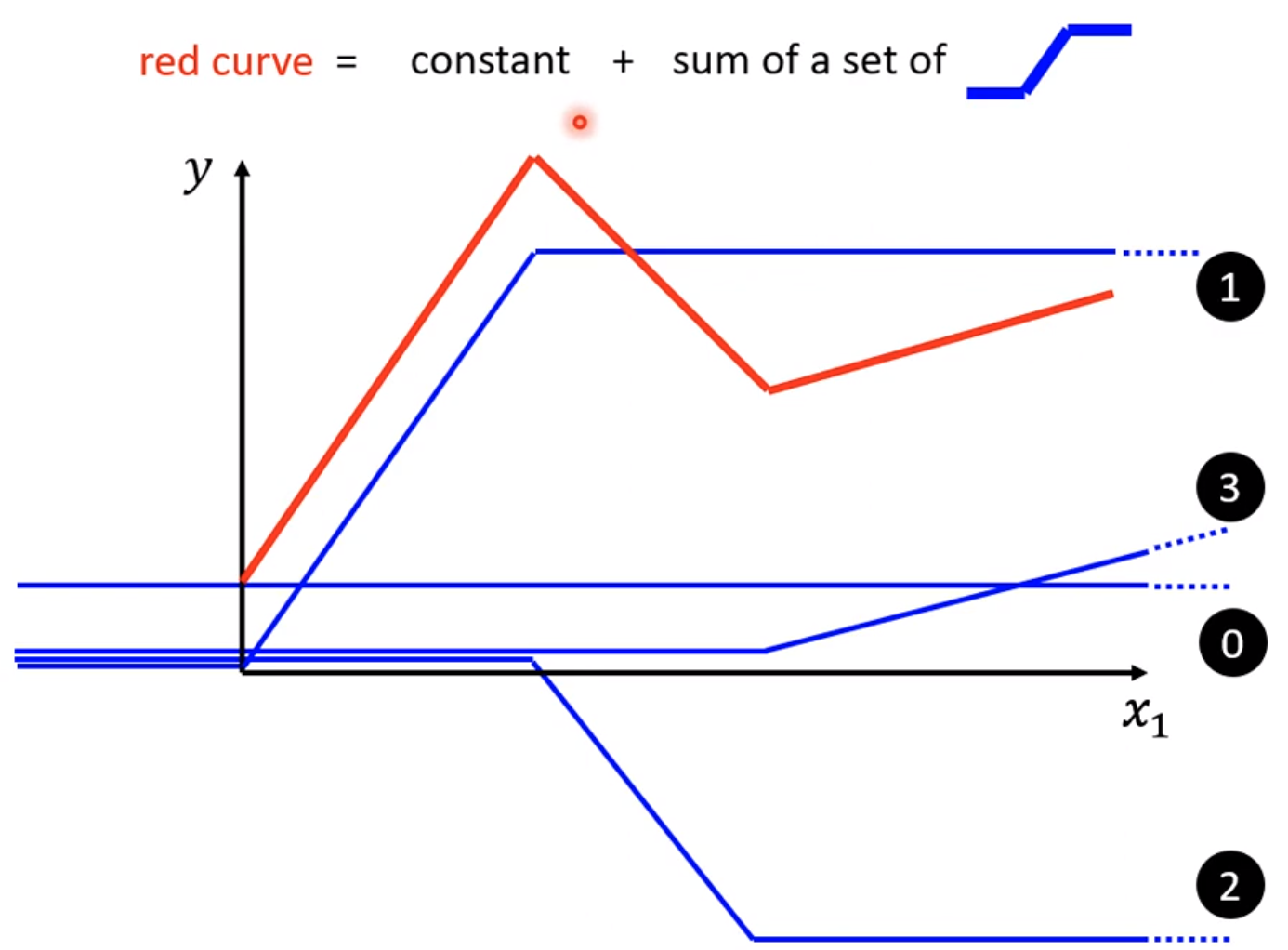
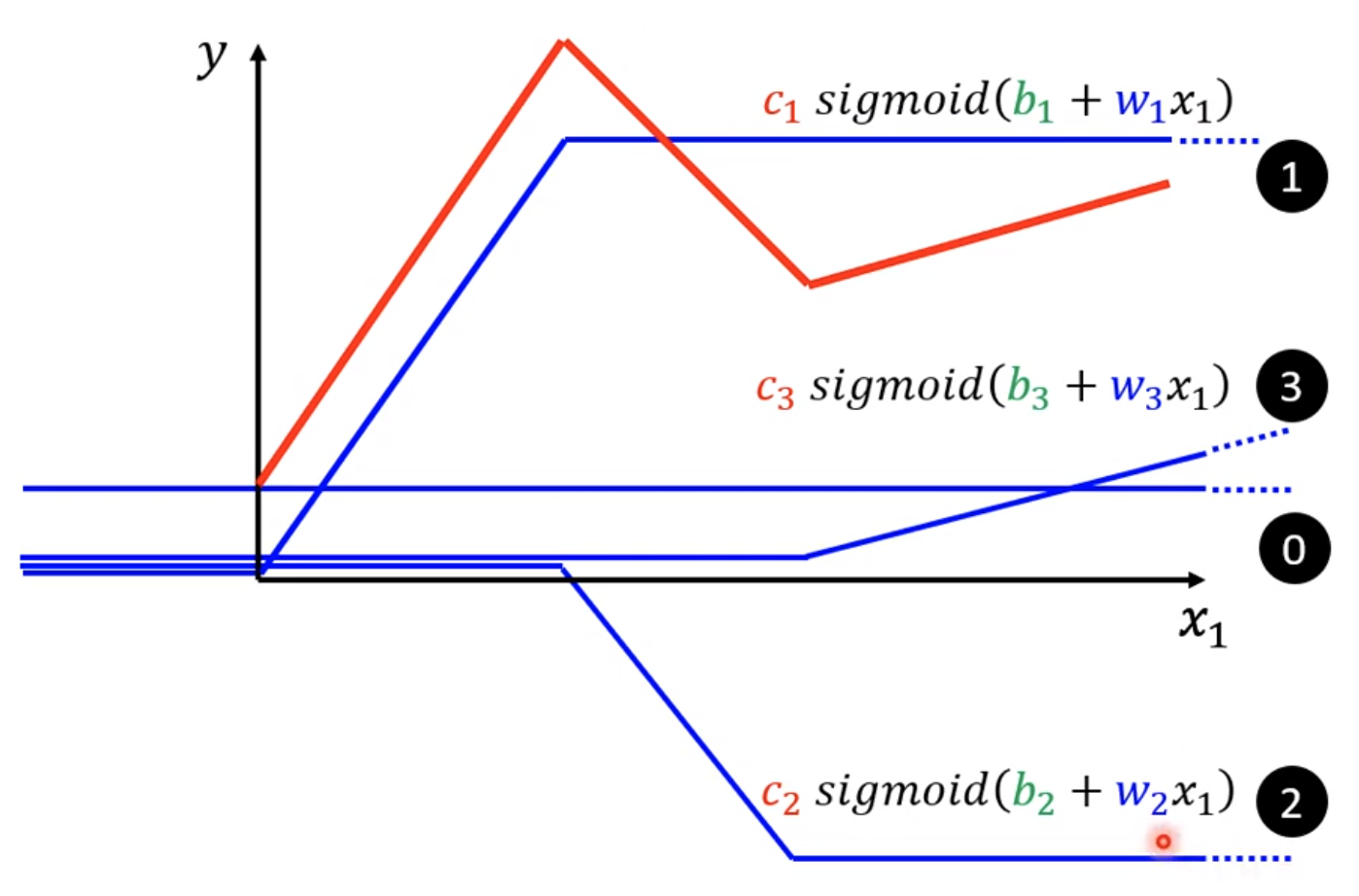
假设真实模型为红线所示,那么可以看出这是三个分段线性函数组成的组合函数
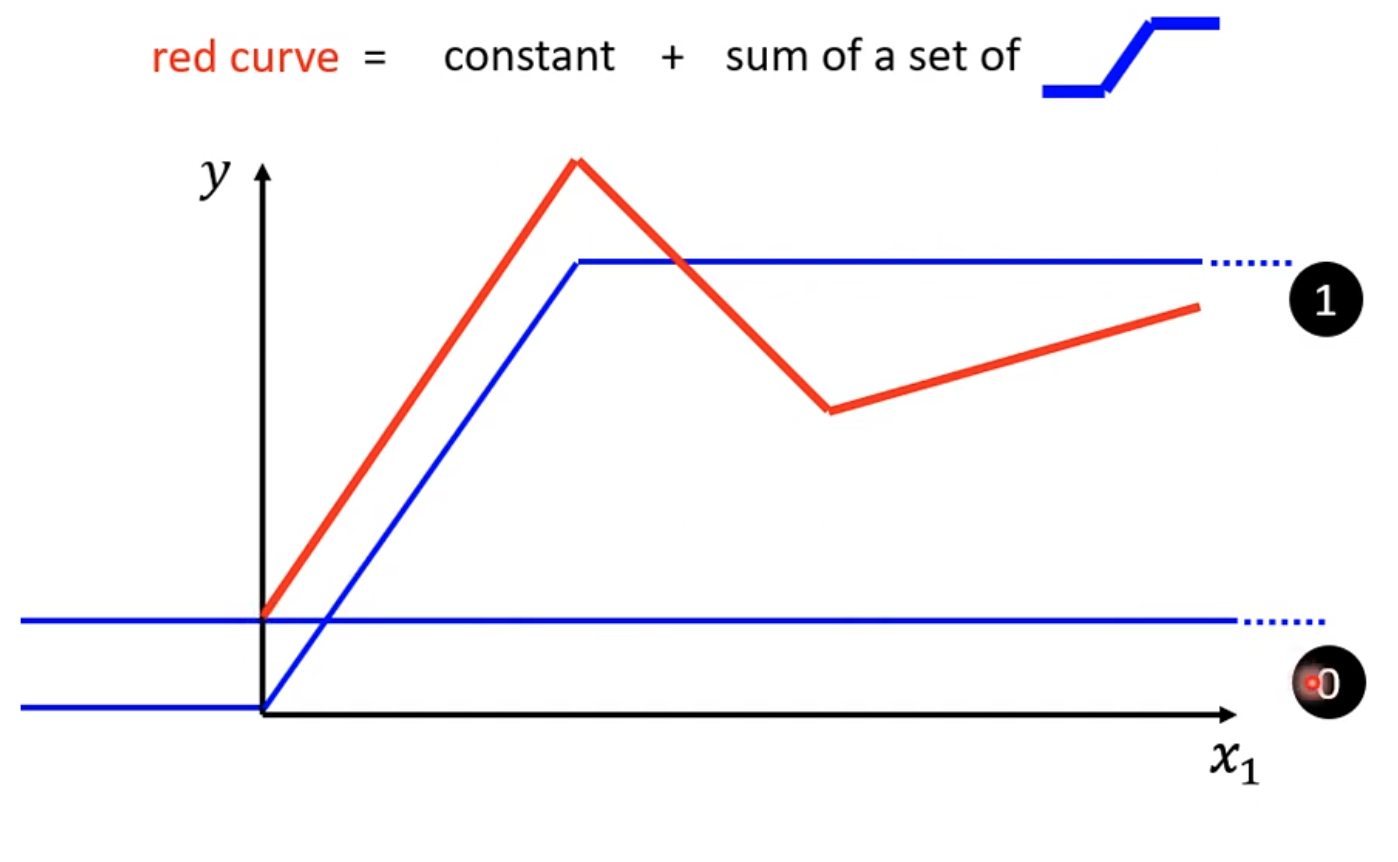
那么第一段红线就可以由0线+1线,0线就是$y=b_{1}$的函数,而1线在从0到峰顶过程中设置为slope一致,那么就是$y=w_{2}x+b_{2}$那么同样思路可以有2线和3线
1.2 piecewise linear
这种多个线段组成的curver就被称为piecewise linear curve,基本都是常数项加许多线段的组合,只是蓝色function不同。
1.3 beyong piecewise Linear
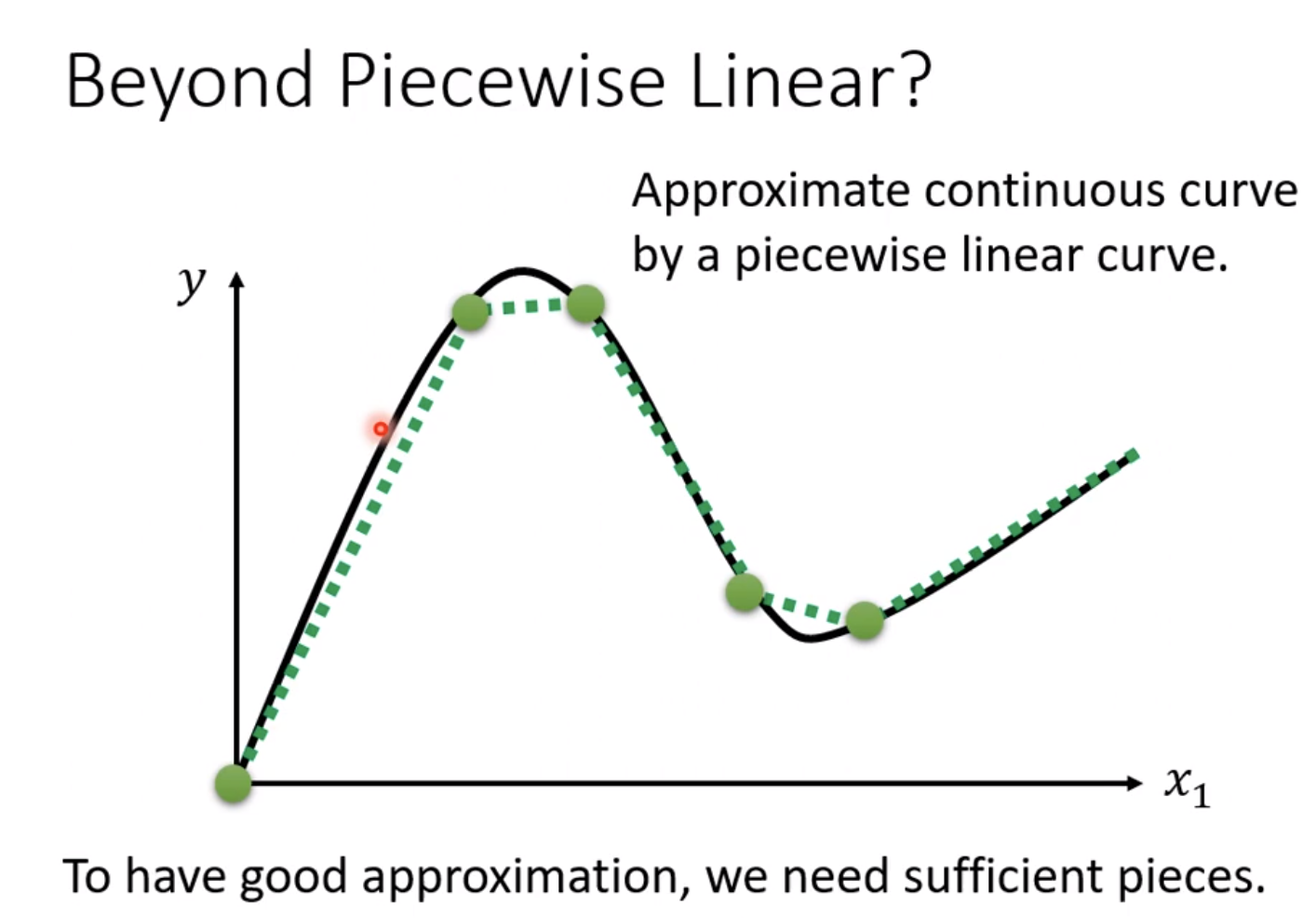
但是有些curve可能是平滑的曲线,但我们仍然可以把它等价为piecewise linear
因为我们可以通过描点近似连线的方式等价。

因此实际上任何一个function都可以通过这种方式逼近。
1.4 beyong piecewise Linear
像这样的图其实可以用一种函数表示,这种函数叫做sigmoid function所以实际可以写成
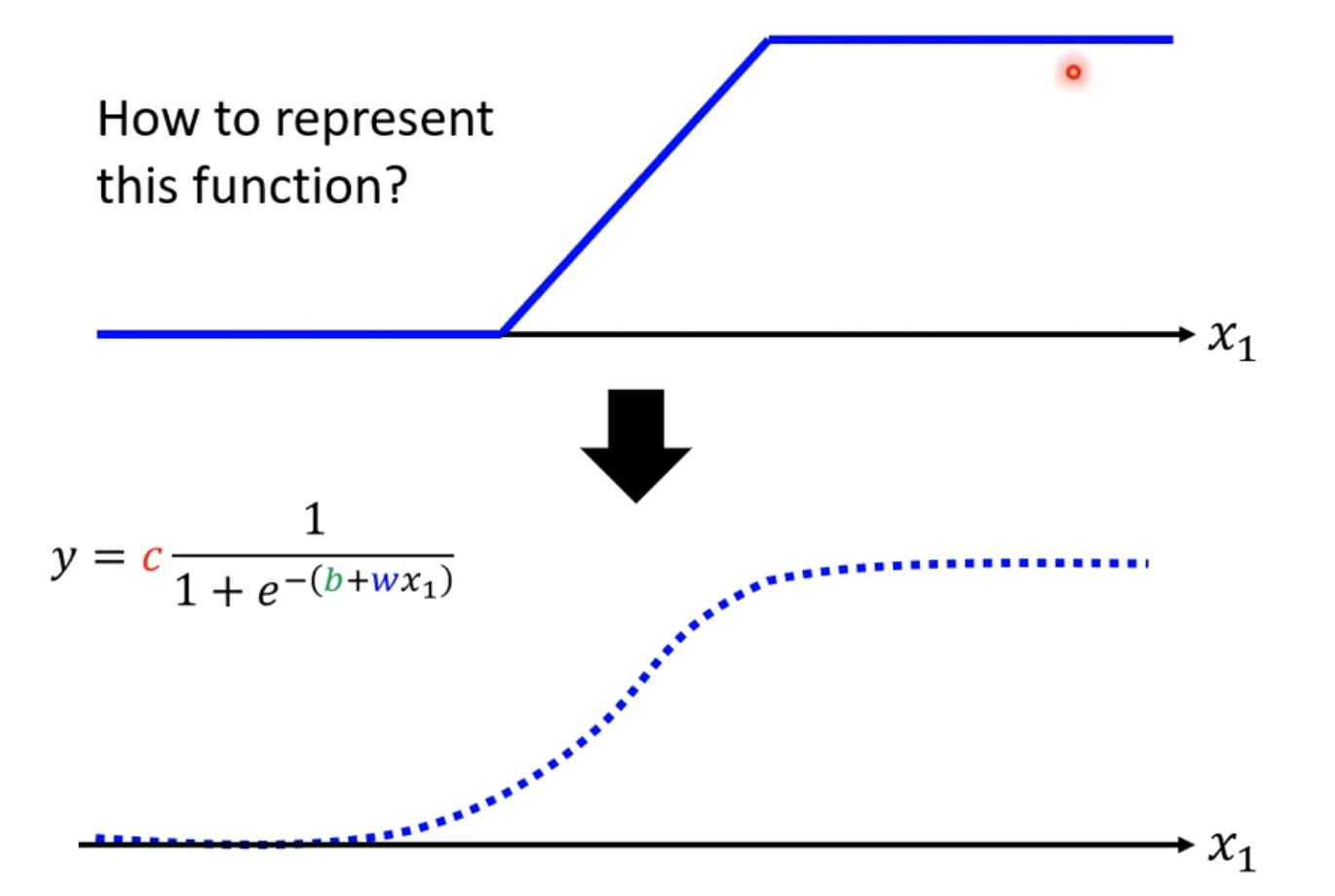
这个蓝色的function常见的名字就是hard sigmoid。通过调整不同的w,b,c来获得不同的sigmod functioon
1.5 differentw,b,c simogid function
通过修改不同的w,b,c就可以拿来近似各种不同的continuous的function
w的变化导致斜率,b的变化会导致偏移,c的变化会改变高度

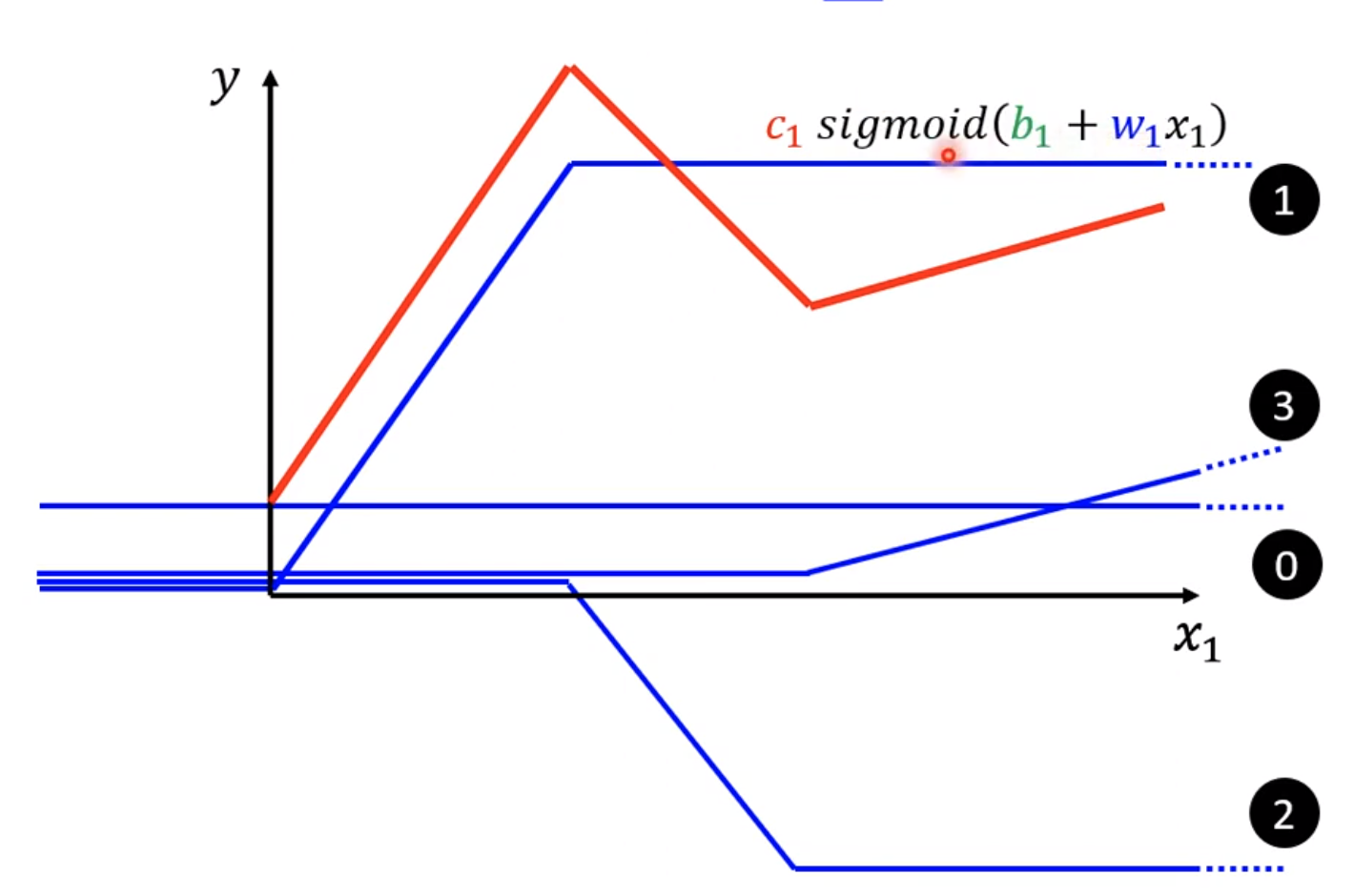
对于红色的组合函数1,就是通过3+2+0组成,那么3,2都可以写成sigmoid,只是拥有不同的b和w,而0就是一个常数,因此可以写成单纯的constantb
那么组合后的公式就是:
$$
y = b + \sum_{i}^{} c_{i}sigmoid(b_{i} + w_{i}x_{i})
$$
2. New Model: More Features
这个模型其实还是有一定限制的,作为linear function的限制,因此又被称作为model bias。
假设天数是28天,天数设为j,那么可以写成以下形式
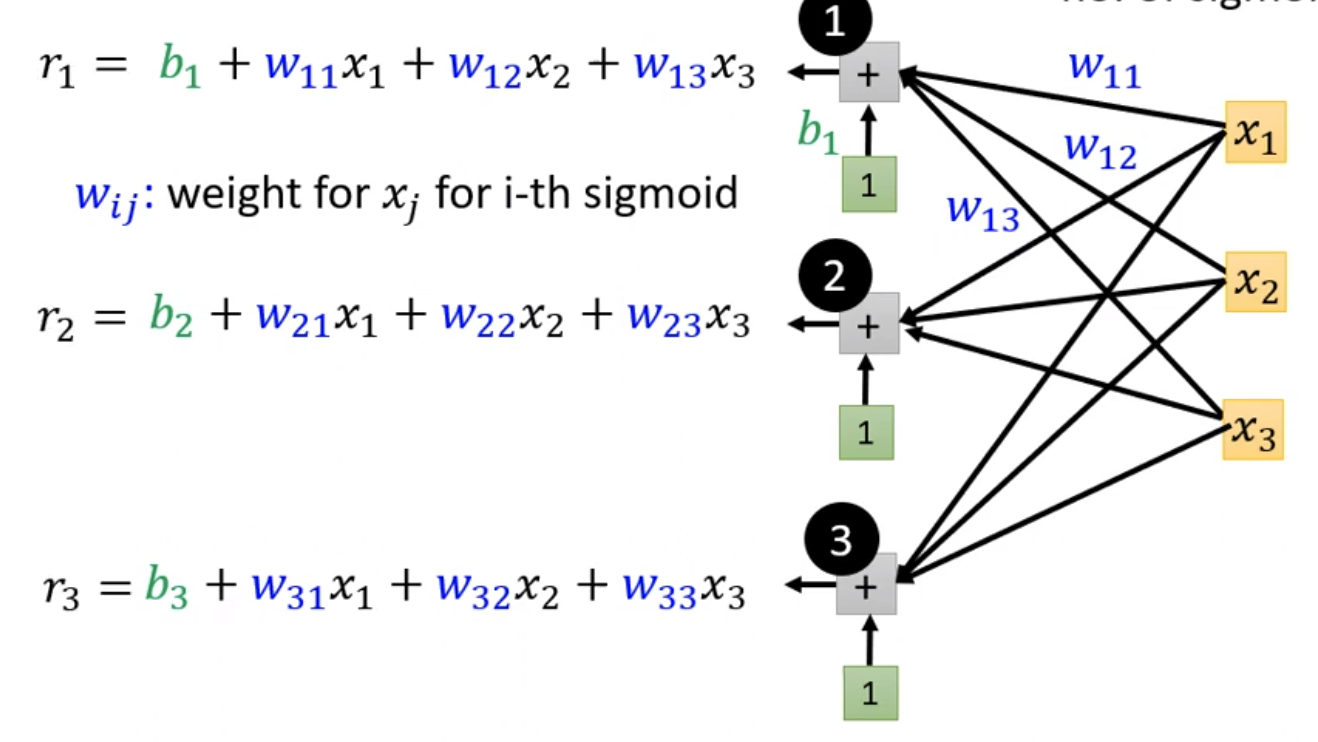
如果j为1,2,3,那么x1代表前一天观看人数,x2代表
两天前观看人数,x3代表三天前观看人数。那么蓝色框部分的计算可以写成以下图所示:
对于这部分的计算其实可以用更简洁的方式计算,也就是线代的矩阵计算。这也是深度学习为什么蓬勃发展的最主要原因,矩阵运算较为快速,可以使用gpu,技术本身没有什么大的进步。
对于r最终需要通过激活函数也就是sigmoid function来获得a
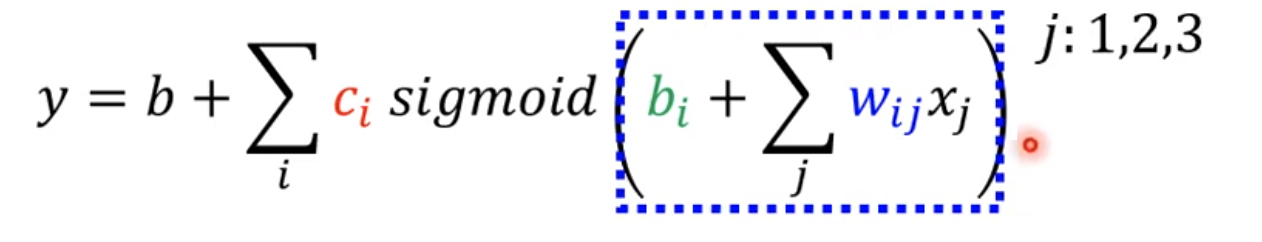
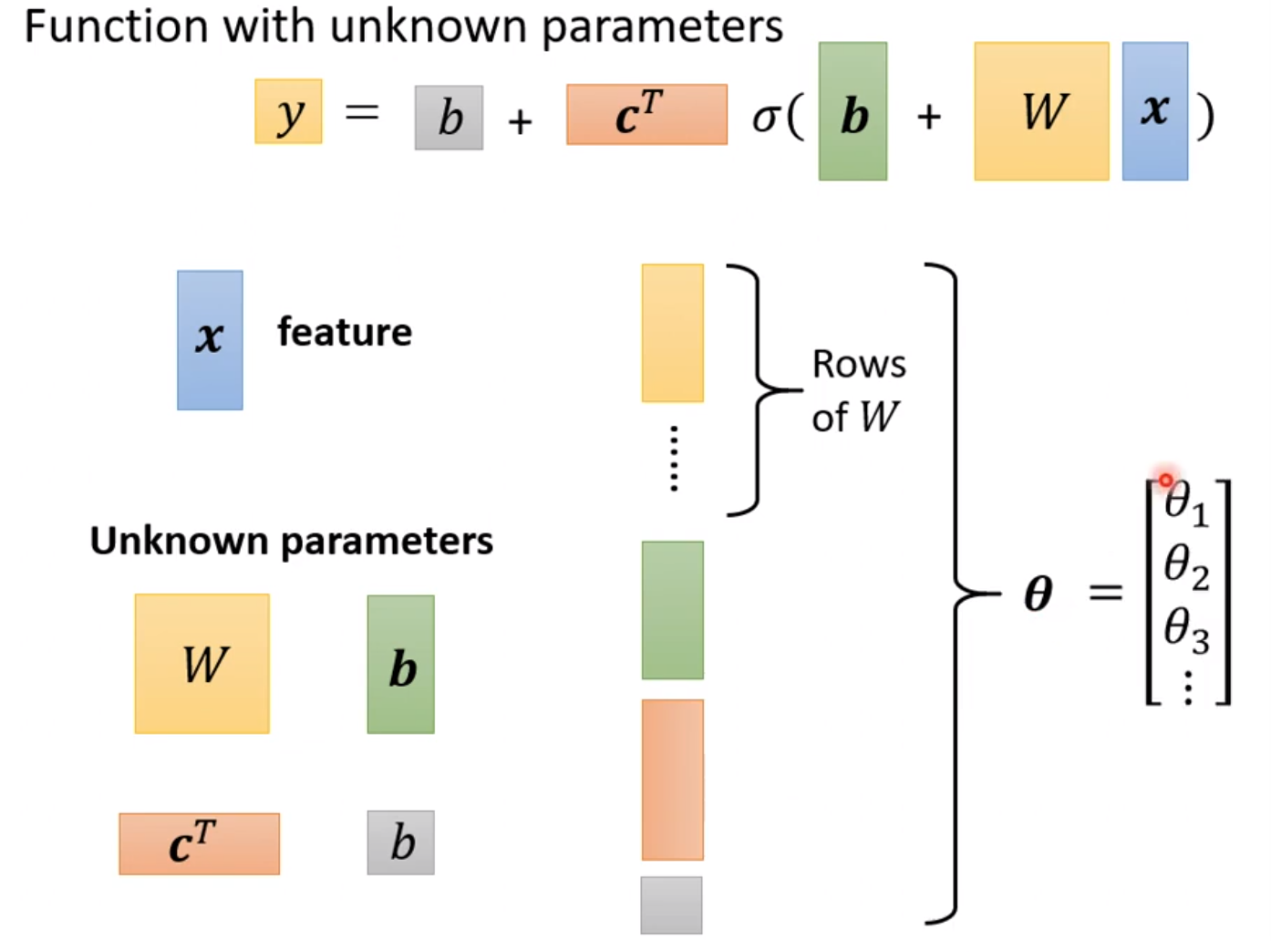
2.1 functions with unknown parameters
我们现在重新定义未知惨呼,那么x就是feature,那么未知参数就是以下这些
把这些未知参数拉直后就可以获得一维向量,那么就可以得到一个新的参数$\theta$
2.2 optimization
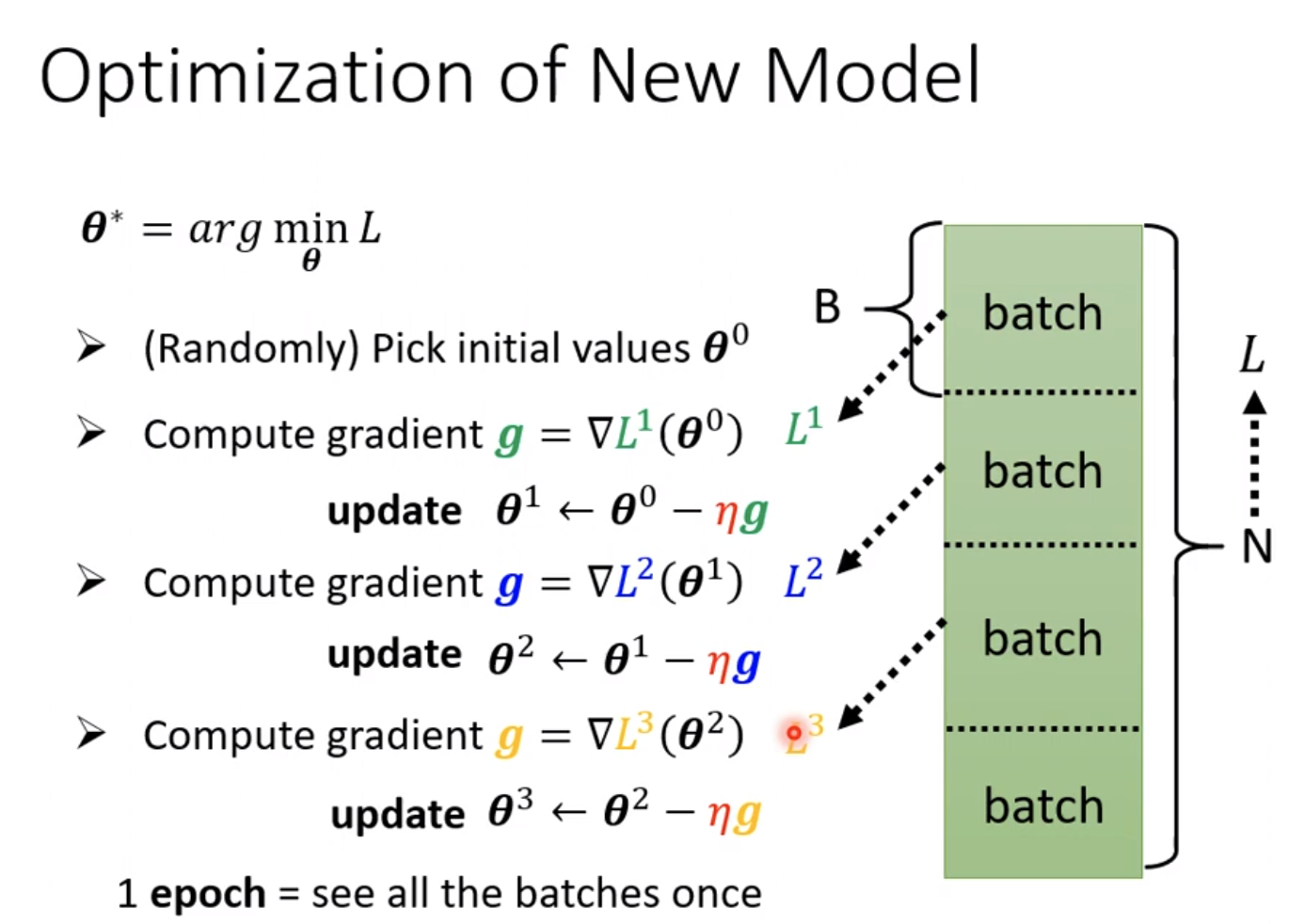
当参数多起来后,就得找一个优化方法,比如gradient descent来找到loss最低的参数。
那么loss就可以写成跟$\theta$相关的函数,要找的就是loss最小的参数值,参数值可以确定模型,因此就可以获得关于这个问题的函数模型。
所谓梯度的方法,就是做微分的过程
初始自己选择一个参数来开始做微分,获得g1,更新参数的步骤就是根据做微分的结果,可以获得参数$\theta$,然后循环往复。
在做gradient descent的时候,我们并不是一次性把数据完全喂入模型获得梯度,而是把数据划分成一个个batch。对于每一个batch做一次的梯度,因此每个batch具有一个loss值,假设batch为三组,那么loss就是同样三组,为loss1,loss2,loss3。所有的batch都计算完就叫做一个epoch,每一次更新参数就叫做一次update。
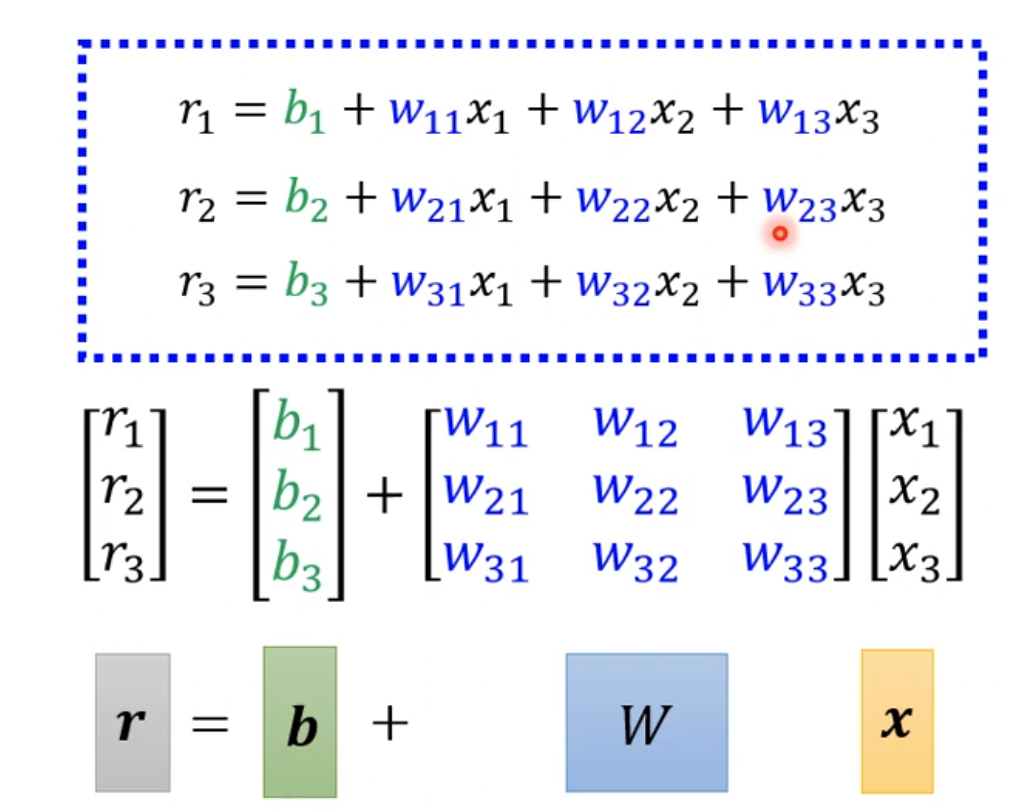
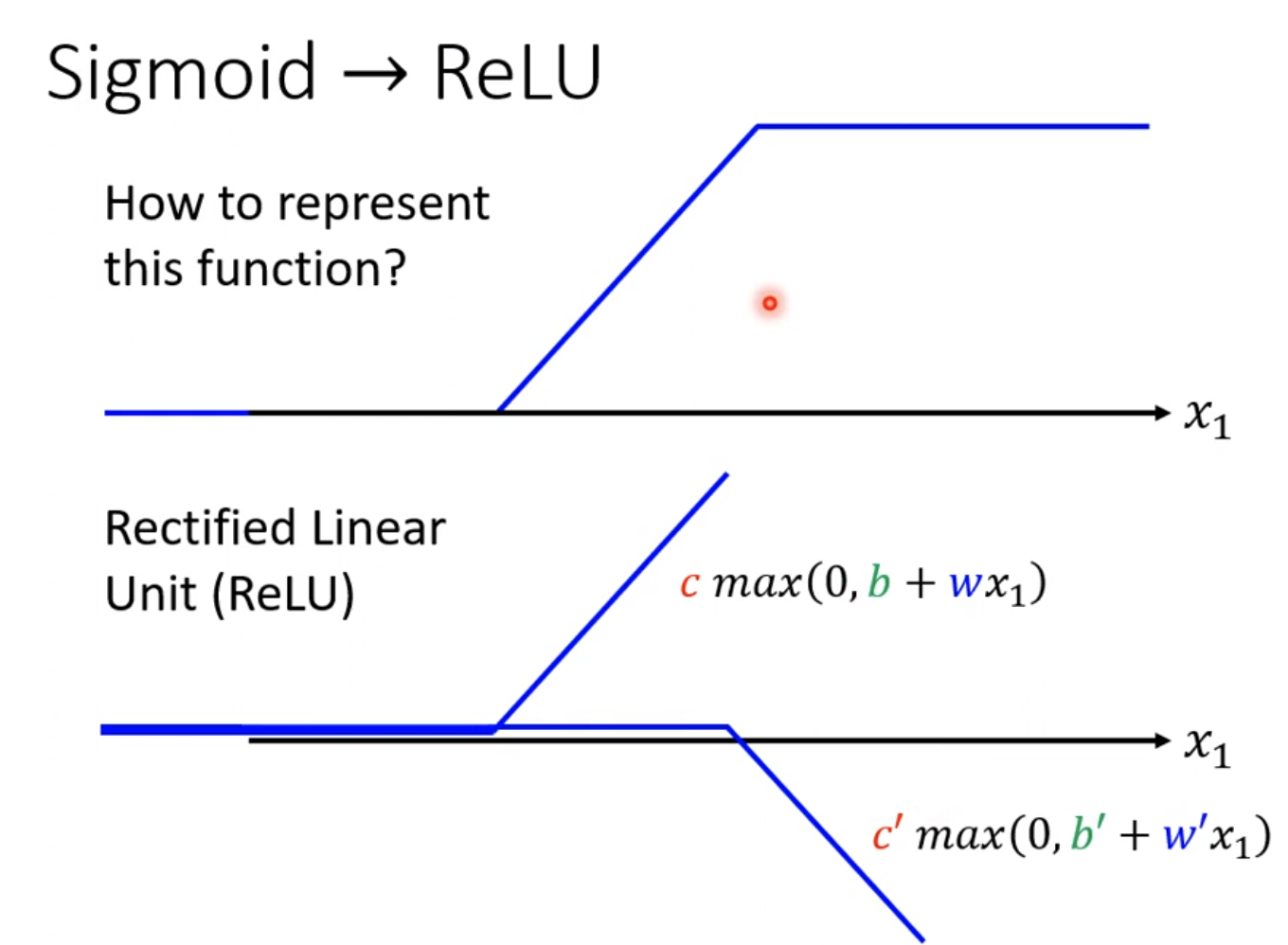
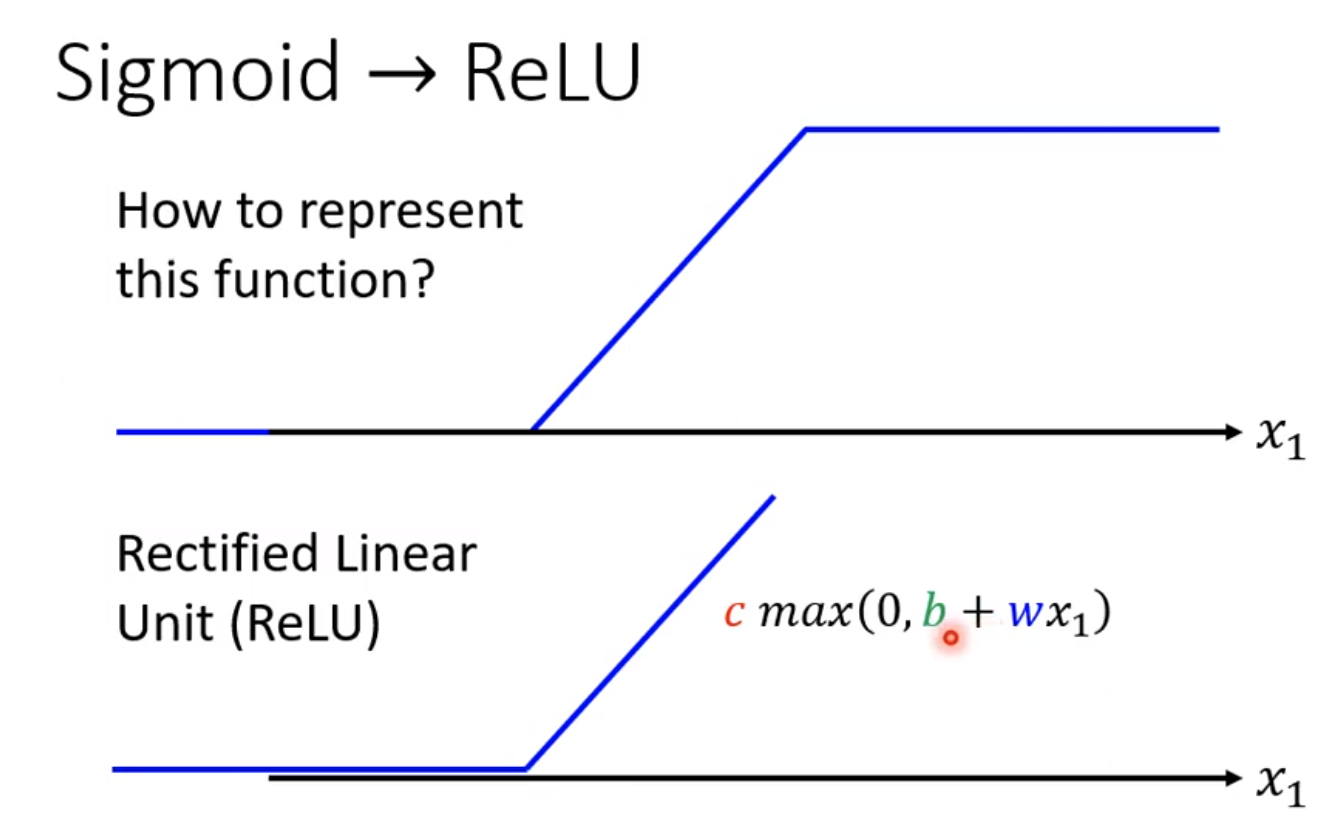
2.3 sigmoid->relu
sigmoid作为激活函数是比较限制的,sigmoid函数其实可以看做两个relu函数相加。
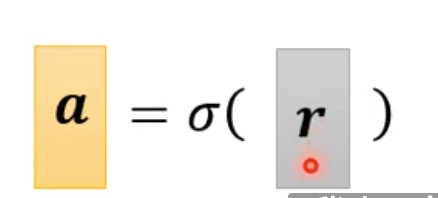
relu的输出最小值是0,因此可以防止小于0的输出。模型修改的话,就把sigmoid改成relu,因为sigmoid等于两个relu函数,就可以写成relu*2
那么relu更好呢还是sigmoid更好呢?对于youtube channel这个问题,实验数据结果如下
2.4 relu experiment results

可见如果用的relu模型越多,验证集和训练集的loss都有明显的下降。
除了可以增加模型的relu次数,也可以选择怎更加模型的层数,随着模型层数的增加loss也会变化
3. 为什么被称为deep learning?
因为要取个fancy name来吸引投资,吸引不懂行的人,告诉大家这就是AI,实际上AI所做的事情不过是计算,达到真正的人工智能还需要非常非常远的距离。
每年新出的模型层数都是越来越高,那么是否代表模型越复杂效果越好呢?
4. 过拟合
其实并不是,如果我们把模型的层数很复杂,那么模型会在训练集效果很好,但是在测试集效果会变差。而这就是过拟合