segnet任务
1. 训练segnet
segnet是在vggnet基础上的分割类模型,可以用keras搭建,caffe搭建方式过于复杂
因为指静脉数据已经分类好了脉络和图像,因此本次不需要通过labelme来标签,只需要调用模型,但是对于数据要进行预处理,生成独热码方式的标签的Numpy数据
2. 预处理的坑
感谢杨帆帮忙处理解决了关于转换one-hot编码问题
本次训练集121,验证集20,张,训练集和验证集都打好了标签和图像
先进行数据读取
2.1 图片数据读取和修改size
1 | img = cv2.imread(name) |
2.2 读取标签数据和修改size
1 | label = cv2.imread(label_path, 0) |
标签采用灰度图的读取方式,并且将size改为原图的一半大小
将label图小于127的值设为0,大于127的值设为1,就可以实现图的独热码转换。
网上的方式是通过初始化张量后,在对于每一个张量遍历进行修改。
2.3 关于报错
一开始选择了用height, widith作为初始图片来修改,但是在喂入模型训练的过程中发现了bug,原因是在模型训练过程中可能并不能对上,这里我通过pycharm debug一步步看数据变化方式时并不清楚原因,后来才明白每个模型的参数设定图片变化应该修改,否则通过conv2d可能会导致失败
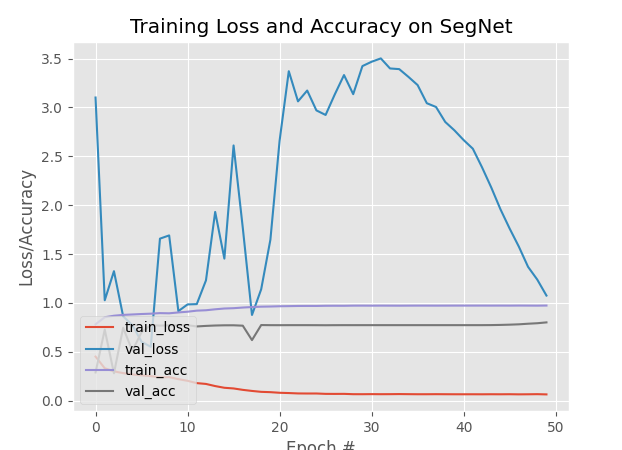
2.4 训练图
3次训练后的图

目前正在等训练100次后图的变化
3. 画loss,val,train_acc, val_acc图
这里用的是matplotlib的ggplt包绘图
1 | plt.style.use("ggplot") |
4. 预测图像及之后要解决的
载入训练模型后,再次进行预处理图像
1 | img = cv2.resize(img, (WIDTH, HEIGHT)) |
然后使用model.fit输出图像,因为会有4个,所以选择第0个图
1 | pr = model.predict(img)[0] |
4. 1 cv2修改size的bug
这里修改size会导致报错,因为cv2修改size必须是float格式,int64不可以转换。将pedicted图像转化为float格式,并且还原原本图像size方便比对。*255是防止图片全黑
1 | seg_img = cv2.resize(np.array(pr, np.float), (200, 100)) |
预测后每张图都是黑的,目前杨帆建议是等多次训练后看是否会有变化,否则在尝试修改,看代码是否哪里有问题。
5. 新训练模型Binet2
binet2是旷视目前研发的去年出的分割新模型,下一步尝试使用Binet2来进行训练,看效果如何
BiseNet2在Cityscapes可达 72.6%mIoU,速度为156 FPS!性能优于DFANet、SwiftNet等网络。并参与了CVPR。
论文链接:
https://arxiv.org/abs/2004.02147
开源代码: